How It Works
INDEX HISTORY ANALOG TO DIGITAL SOFTWARE APPLICATIONS FUTURE REFERENCES
The purpose of speech recognition software is to take a digital rendering of a sound wave and make meaningful words, or sentences from it. The success rate vary widely depending on the content of the speech:
The smaller the vocabulary, the greater the recognition rate
When speech is in response to a specific, guided question, recognition rates are higher
Learning systems can improve recognition for a particular person's voice over time.
Digitalization:
Speech signals are received from an input device and converted from analog to digital information
Conversion is done using a process called digital sampling
Digital sampling breaks apart large streams of data into short intervals for analysis
Software will then measure the amplitude of the sound wave and convert it into a binary number with a given bit-length of at least 8 bits
Representation:
After digitization, the signal is classified into a set of codes that the system can understand. Typically, these measurements are transmitted every 10-20 milliseconds to make sure that the system can differentiate between words. The system then converts these samples into acoustic parameters (AKA waveforms). These parameter values are then used throughout the rest of the process to determine whether the waveforms analyzed correspond to a particular phonetic event that occurs in the phone-sized or whole-word reference unit being hypothesized. There is no strict boundaries where the stage of identifying and searching begin and end. It is all one continuous event.
Representation of the Word "Speech"

Phonemes, the cornerstone of speech recognition:
Speech recognition software maintains a large database of sample wave structures for every basic component sound used in a particular language (called a phoneme). The given wave is then split up and matched with the closest sample phoneme wave. This is why a system can do better when evaluation the voice of just one person. It can create a database of phonemes that are exactly as the users voice, then match future voice samples against the saved phoneme database. Systems that need to be used by many separate users often use many sample wave forms for each phoneme, and then perform phoneme matching statistically.
Word Recognition out of Phonemes:
Once the phonetic combinations have been determined, the software goes to a database of vocabulary words with phonetic spellings. The combination of phonemes for the given wave portion is matched against the database of the vocabulary.
The Use of Grammars:
All spoken languages have a certain set of rules on how words and utterances are combined together to communicate ideas. Therefore all speech recognition software makes use of Grammar rules which are programmed in to reduce the error rate.
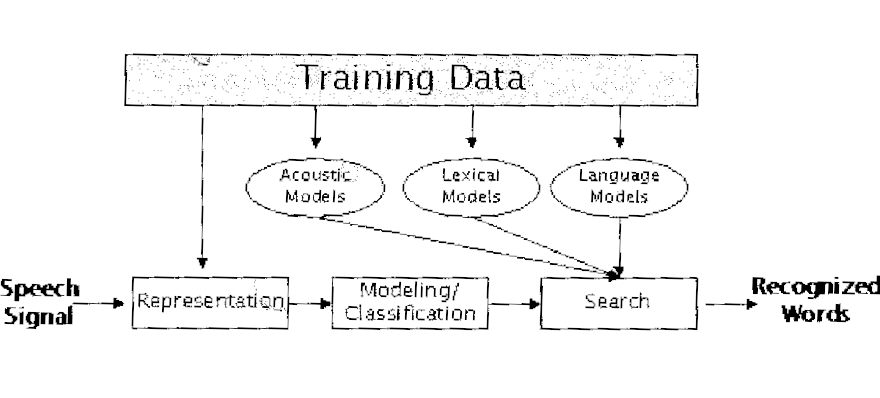
Modeling, Classification, and Search
Results taken from earlier stages are now analyzed by the system to generate the most likely word candidate. Training data, based on the parameters designed in the system, determine both the representation process and the depth to which acoustic, lexical, and language models are applied to determine the correct word. The dominate recognition algorithm of the past 15 years has been the Hidden Markov Model (HMM). A HMM is a doubly stochastic model, in which the generation of the phoneme string and the frame-by-frame, surface acoustic realizations are both represented probabilistically.
The HMM:
The HMM is the powerhouse behind speech recognition. It is popular for two key reasons
It is very rich in mathematical equations
It works incredibly well
for all the information you will ever need to know about HMM's click here
|
|
©2003 St. Norbert College |
Email the Webmaster |