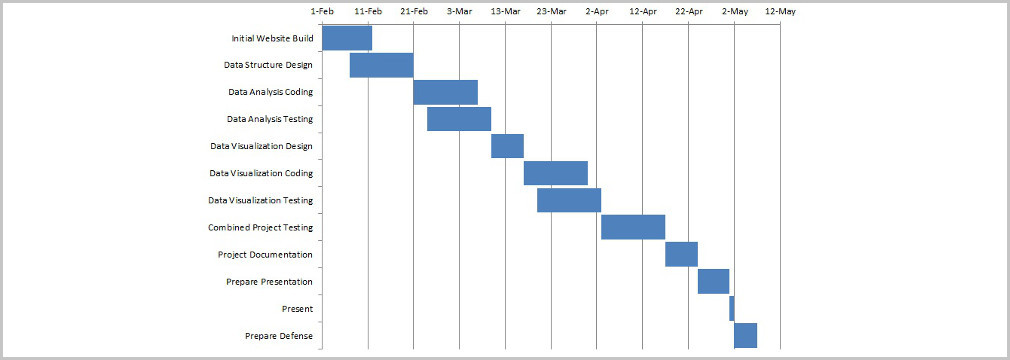



About the Project
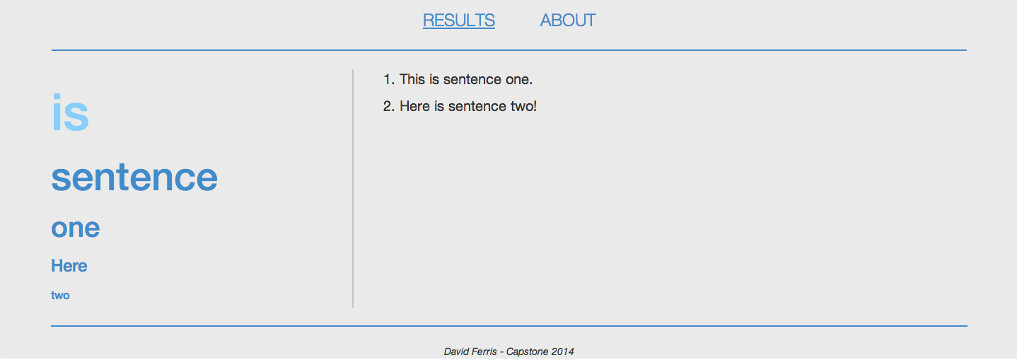
Online surveys often have open-ended questions or comment sections with text fields. When hundreds or thousands of people take the survey, how are those administering the survey supposed to gauge the results without reading each survey, one-by-one?
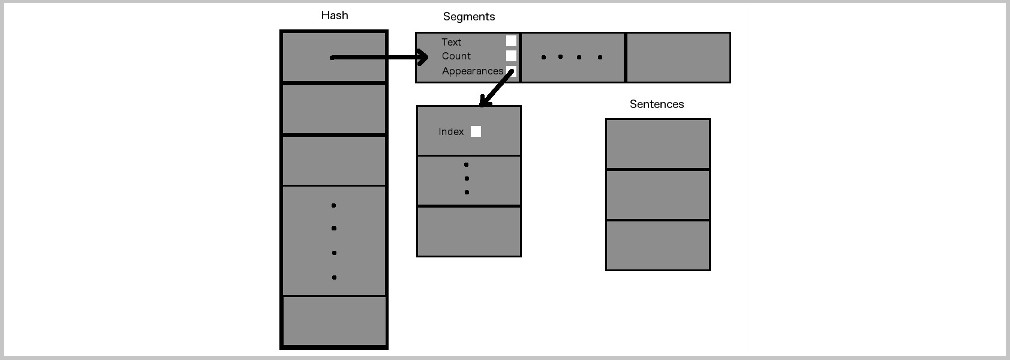
The goal of my project is to analyze a large sample of text and identify key words/phrases and the frequencies with which they occur. This way, I will be able to provide a visual representation of the words/phrases that are used most frequently, which will make it quick and easy to gain a general overview of the text. In the case of a survey, this would be useful to represent the opinions of the surveyed population
Philosophy
My first exposure to computer science came when I was about 8 or 9 years old, watching my brother write text-based games in Q-Basic. At the time, I found programming to be boring; too much hunting and pecking for too small of a result. I didn't delve into programming again until my first semester at SNC.
I began my time at SNC as a physics major, which didn't last very long. CS110 was a requirement for the physics program, and after 7 weeks of C++, I was a computer science major. I was drawn to the field of computer science by the addictiveness of coding. The freedom that comes with coding - being able to accomplish goals via a large variety of ways - gives the feeling that you can make almost anything you want to. Some weekends I would think of an idea for a program and then spend hours working on it, just on a whim. The addictiveness of coding has motivated me to pursue a career in software development.
Another aspect of computer science that draws me in is the rapidly-advancing nature of the field. It seems like every-other day there has been an advancement in technology or a software innovation that allows for a range of further innovation. You never know what is going to be possible in the next 10 years, 5 years, or even the next year. I can't think of many other professions where this is the case.