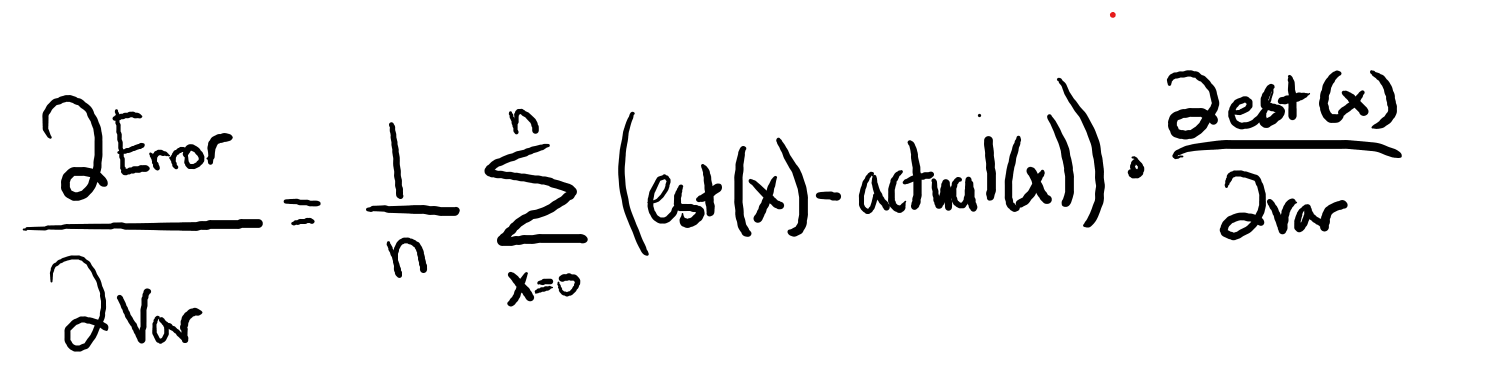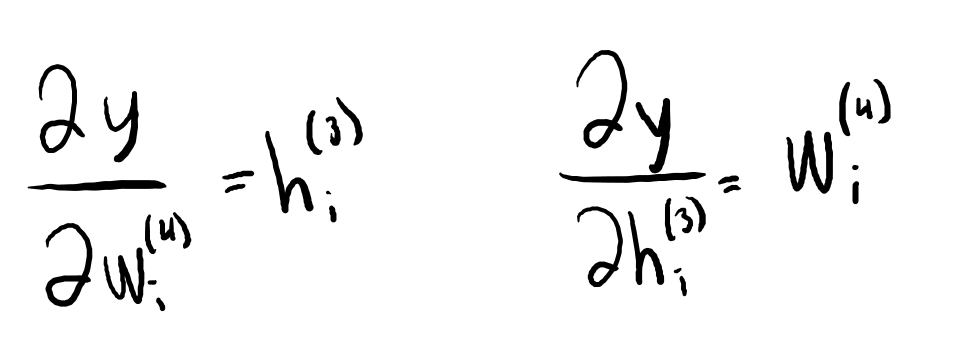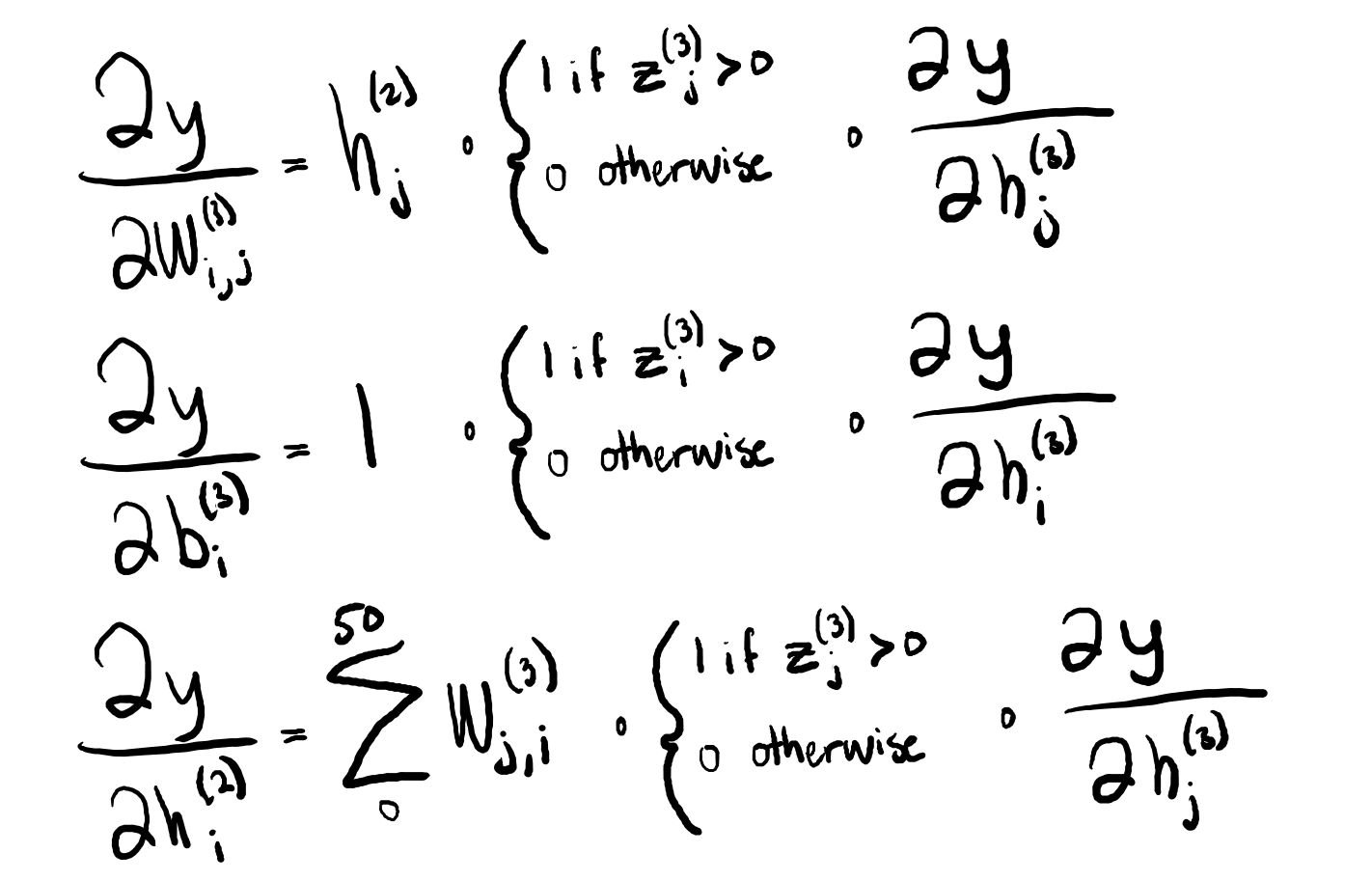PICKING A GAME
February 1, 2024
First week done! After doing some research on two-player perfect information games, I settled on two games that look promising. Santorini is a relatively new game that looked fun and interesting, but could potentially have too big of a state space to effectively train a ANN to play it well in only a single semester. Othello (also known as reversi) is a classic, safer choice in the event that Santorini is overly ambitious. I ended up programming the basic logic for both games for the time being as I do more research on training and building my artificial neural network.
FOUNDATIONAL WORK
February 8, 2024
Continuing from last week, I optimized my code for the game Santorini. The game currently allows for two human players to play against each other. Eventually, I will need to allow a game to be played with a combination of different player types. The current state of the program is handling all edge cases and bad user inputs, which is a good foundation to build on. I also have began the development of another player type that makes a completely random (but valid) move choices. I have cleaned up most of the experimental code I built prior to ensure I have reliable functions with clear documentation. Most of the functions are used to verify all of the games rules are followed across all stages of the game.
DESIGNING A SIMPLE AI
February 20, 2024
This week I finished development for a random player, and allowed games to be played in any combination of human and random player types. The random player first randomly select one of it's workers, randomly generates a change_in_x and change_in_y (repeating this step until a valid move is found), and moves the worker accordingly. It follows a very similar process for placing tiles.
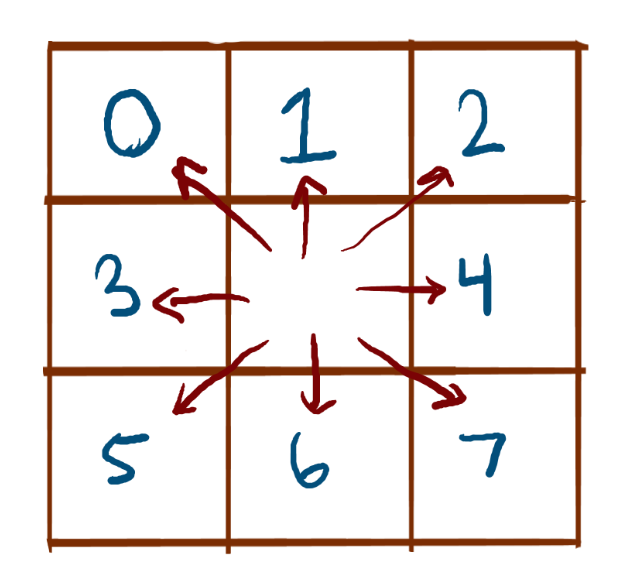
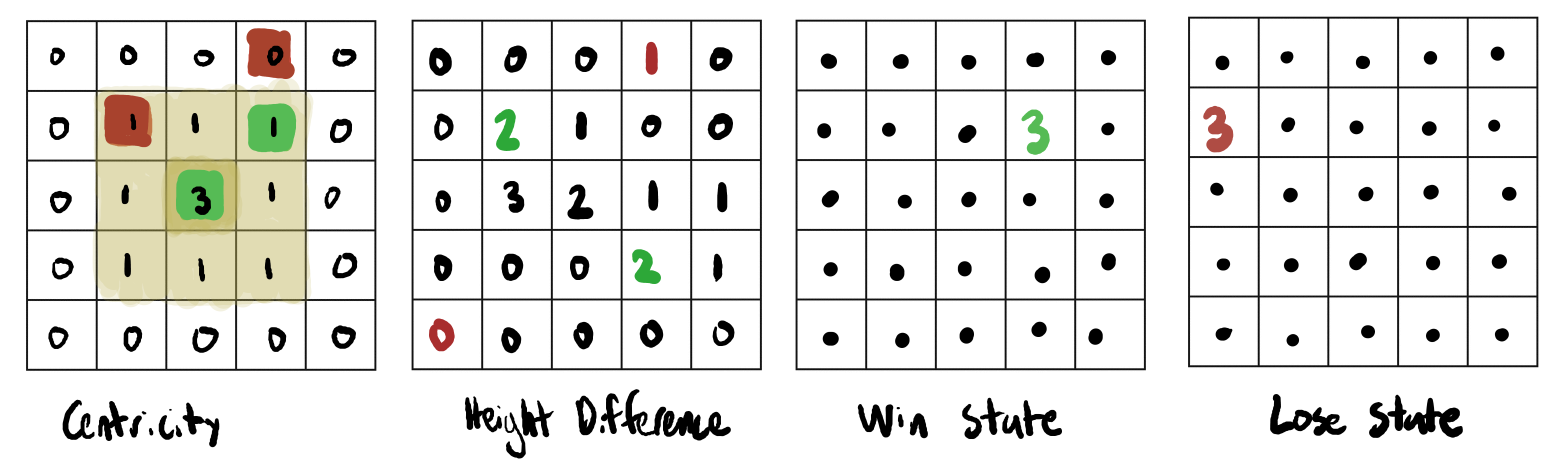
In order to develop the next player type, I need to have a firm understanding of strategy in Santorini. The next player is a simple AI that has a decision making process following basic heurisics/strategies. This AI would employ an evaluation function which determines the best move to make by assigning a high value to boardstates which maximally followed the heursitcs. As a result, this AI would follow basic strategy and would almost certainly be better than a purely random AI. The choice of these heuristics would dramatically effect the performance of the simple AI player, but selecting 'good' heuristics is subjective and must be guided by good intuition of the game. A basic heuristic is "one-step lookahead", which evaluates whether or not there is a winning game state within one move, and always takes it when avaliable. In the context of Santorini, if one of the player's workers can move to the third floor, it will always make that move. Another basic heuristic is "two-step lookahead", which evaluates the best position within two moves. In the context of Santorini, if the opposing player has a winning move on their next turn that can be blocked by the simple AI, then that is the best move to take.
It can be difficult to determine more nuanced heuristics. For example, the optimal play from an offensive standpoint would be to move upwards whenever possible. From a defensive standpoint, it would be best to keep the opposing player from moving upwards whenever possible. Taking both of these ideas in account, a 'good' heuristic to include in the evaluation function would be one that considers the height differential between the two players, which takes both the defensive and offensive in consideration.
While I'm still figuring out the specific implementations of the heuristics, I've decided which ones I would like to follow. My simple AI should (1) take a winning move when possible, (2) block the oppositions winning move when possible, (3) maximize the height differential of the players in favor of the AI, (4) attempt to stay central to the board to maximize avaliable moves, and (5) maintain an optimal distance from the opposing workers.
ANN FUNDAMENTALS
March 1, 2024
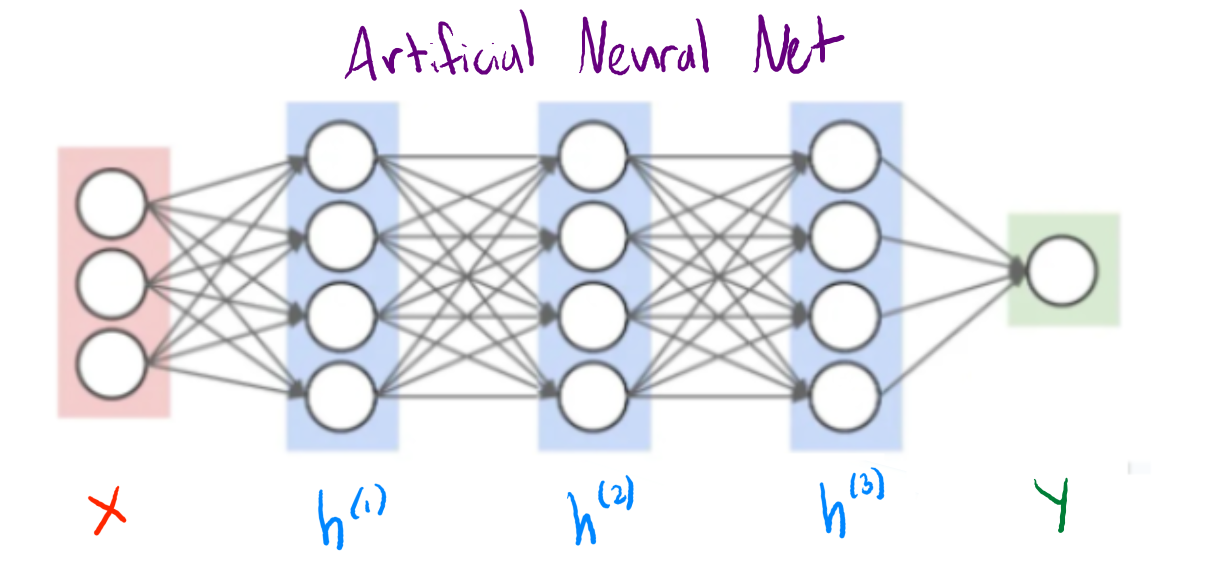
As I implement the design of my simple AI, it has become increasingly more important that I have a solid understanding of Artificial Neural Networks (ANN), which my primary AI system will utilize. In my research this week, I have done some research about ANNs and how to actually develop one. There are a wide variety of ANN libraries in C++, of which I have been sorting through the documentation and assessing which best suits my programs needs.
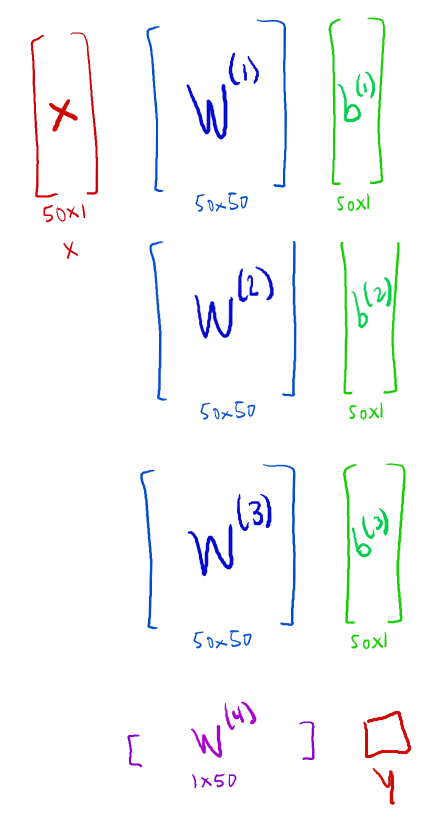
The ANN of my primary AI will essentially serve as that AI's evaluation function. Provided a boardstate, it will produce a value that attempts to accurately estimate the likelihood of winning from that position. The network takes the boardstate as a vector for input, and it subsequently performs matrix transformations and pruning to refine this state into its 'value'. The magic comes from discovering the proper matrices to use in these transformation, and selecting the correct weights for them. I can improve my ANN by reducing the sum of the squared error (difference between produced and expected 'value' of a state) across all boardstates.