Stock Market Sentiment Analysis using NLP

Project Description
To buy or not to buy? To sell or not to sell? Investors are making these decisions daily with imperfect information. The market is dynamic, with many factors influencing its behavior. The sheer volume of information prevents a user from gathering much of what is needed to make an informed decision.
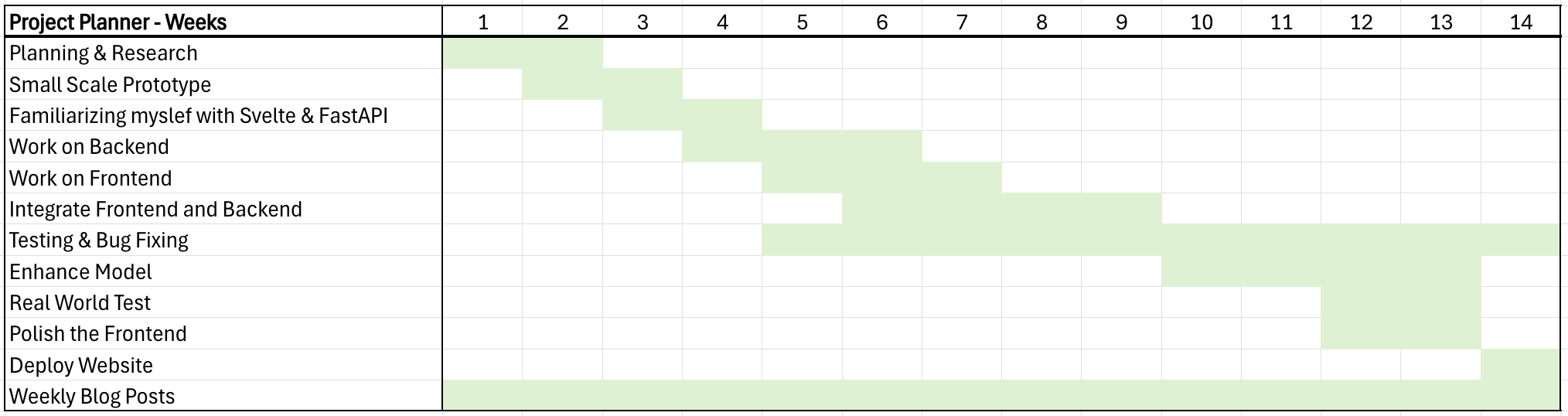
- Identify appropriate sources of information regarding stock prices and trends as well as general market trends.
- Organize and clean the data.
- Explore semantic analysis techniques and implement a model that will support predicting short-term and long-term behaviors of specific stocks or classes of stocks.
- Allow the user to adjust how the data and results are displayed.










Presentation
Philosophy Statement
Initially declaring myself as a Biomedical Major, I would be surprised if someone told me that I was now taking my Computer Science Capstone here at St. Norbert College. Like every other kid, I was really fascinated by technology in general, especially smartphones and desktops. After being uncertain of where my future in Biology would take me, I decided to pivot my area of study to Computer Science and the journey ever since has been nothing short of rewarding. The ability to bring into reality something you just think of is something that you really begin to appreciate the more you do and is something that still amazes me to this day. Every project, every program and every line of code has taught me to problem solve in creative and innovative ways and has fundamentally changed the way I approach situations in my everyday life.

Tinto de Verano
My website is live! Found a template online that I was then able to modify the HTML of to make it mine. Currently looking into finding reliable APIs and the vision of what I want my final project to look like. I hope this allows me to settle on a programming language to use as well as a framework. I do want to come up with a workflow chart by next week and also hopefully start playing around with a few models to get started. I am a little worried about the front end of things, but we'll cross that bridge when we get there.

Milwaukee
This week I worked on familiarizing myself with NLP by working on a small scale project that used a Hugging Face model, specifically FinBERT (https://arxiv.org/pdf/1908.10063), that was pre-trained to analyze the sentiment of financial text. It was built by further training the BERT language model in the finance domain, using a large financial corpus and thereby fine-tuning it for financial sentiment classification. I pulled market data on specific companies by using their tickers and ran the model on the summary of the news articles that mentioned said company. I then aggregated the sentiment across all articles that I analyzed to output a final score.

Snoopy
After settling on the my framework of choice, I decided to spend time familiarizing myself working with Svelte. I did so by making a little project that helped me understand the component-based structure, syntax and reactivity that comes with Svelte as well as working with .svelte files. I wish I was able to expose myself to FastAPI as well, but I wasn’t able to. And so, that’s what I plan on doing this week.

Roulette
I spent this last week finding more direction with the specifics of my project which involved understanding how encoder-only models (BERT) work. I looked into concepts such as word embeddings, positional encoding, self-attention and finally context-aware embeddings. The model I will be using - FinBERT, is the BERT language model with a dense layer attached to the end that helps with the classification of the set of tokens into three categories - positive, negative and neutral. I was able to get the source code for FinBERT which means that I can further fine tune this model to achieve a specific task. I could do this by tacking on more layers that take the output of FinBERT and use it as the input.

The Sears Tower
We worked on trying to combat the problem where multiple stocks were mentioned in the same article. This highlights one of the weakness of NLP in that it isn’t really able to distinguish what part of article refers to what stock. So we have now decided to filter out the articles that mention more than one stock and feed it into a LLM to do the analysis on those articles. We still, however, are planning on passing the articles that mention only the stock of our interest through the NLP model. I almost have the workflow ready for this in python.

Free Bird
I spent the weeks around and after spring break implementing the workflow that would allow us to categorize and prompt an LMM to do the sentiment analysis for us. After discussions with the faculty mentors, we decided to shift gears into the data and the data modeling side of things. This includes how I was planning on getting historical prices for stocks as well as finding relevant historical news articles.

Remontada
Kind of all hands on deck now with my project. The end is near. I was able to grab historical data for the top 100 companies in the S&P 500 from 2021 from a Yahoo Finance package. After cleaning the data I received, I began to search for the right news API to retrieve our news data. This took much longer than I would've liked. Different APIs have different restrictions, different ways of delivering data and ultimately serve different needs. I was able to narrow it down to two APIs and I think the one we're going to end up using is Alpha Vantage. Something nice about the news articles retrieved by this API is that for every article that they store, they also store for each company mentioned in the article a relevancy score as well as a specific sentiment score for said company. We might leverage this. I'm now writing the script to scrape all my sources to build the dataset I'm going to train my model on.

Love
After writing the script to build our data set, we were able to get a premium subscription for the Alpha Vantage API. I then ran my script that, for every selected company, went and found news articles dating back 5 years and then stored the average sentiments for each day in the data set. This took a few hours to run. Now that we have our “scored” dataset, we have to decide on how we want to predict the actual stock prices.

Mariachi
For our model, we settled on using the open price for the particular stock, dow jones open for the same day and the sentiment as predictors and we also decided to use a windowing approach - where we used the data for the past 30 days to predict the 31st day. We played with both, trying to predict the price, and then also trying to predict whether we think the price of the stock would go up or down. We found much better success while trying to predict the price itself. As for the model, we went with a RNN, more specifically a Bidirectional LSTM because of their ability to learn long term dependencies.

Sabastian Sawe
Now that we had our model, I needed a front end, quick. I spent a day familiarizing myself with Flask and then got started working on the UI. I think adding the little headline box at the top really helped with actually seeing what article headlines and sentiments actually look like. I added a stock chart as well as a chart that plotted the sentiment right below it so that users could try and see the relationship between the two charts. Hovering over the data points gives the user a little more information about the specific values all done through chart.js. I plotted the predicted price with a one percent error bar around the prediction since our MAE was about one percent. But that’s it! I think I’m done.
Resume (05/10/2026)