With the presentation finished, I am now focused on gathering all of my materials for submission. I have finished writing my "About" and "How To" documents, and have placed all materials on the "Files" page for download. Versions of each file are available in their original format as well as in the .txt format. I now need to print out all of my files and submit my binder, to officially be finished with my capstone project.
It has definitely been a good semester, I have learned a lot while working through the project. Now I am focused on finishing my the last of my final exams (Operating Systems) and graduation. In less than a month, I will be moving to Sheboygan and beginning work as a programmer at ACUITY. It is bittersweet to be graduating. It has been an amazing four years here at SNC, and I have learned and changed more than I ever thought I would. A chapter of my life is coming to an end, and I am excited to see what the future holds.
Today is the day of the presentations. Over the past couple of days I have finished my PowerPoint and prepared a text file for my demonstration. Because my C++ application does not really display any information useful for the demo, I have decided to run it ahead of time to obtain the resulting text file. During the demonstration, I will show the webpage that results from this text file. This also eliminates the need for me to use an FTP client to upload the file to the server during the presentation.
The text sample that I have prepared is the Software Engineering Code of Ethics. I have had to make slight alterations to the text, to prevent one specific case from occurring. The numbers that appear at the beginning of each principle were causing some small issues due to the '.' that they contain. This would result in one of the digits being a sentence of its own, and the last two being tacked onto the beginning of the next sentence. Because of this, I deleted these numbers from the text.
I believe that my project is at a good stage to present. Hopefully I can speak for as much time as I did when practicing! Wish me luck!
With the deadline in sight, I have made some more slight alterations to my project. I have finally removed all use of the term 'segment' from my files, and am now using 'word' instead. I believe that this makes more sense conceptually. I believe that everything was changed properly, and all the tests that I tried turned out fine. Hopefully I didn't screw anything up while changing terms.
There are still a couple of issues that I intend to resolve before my presentation. The one problem I have with the webpage portion of my project involves the sentence sampling for words that appear in >10 sentences. Currently, a random sample of 10 sentences is generated for each of these words when the page is loaded, and those 10 sentences will remain until the page is reloaded. Ideally, I would like to have a new sample of 10 sentences generated each time that a word is clicked (to reveal its sentences). It seems tricky to call a php function from jQuery, which is what I would need to do to generate a new sample of sentences. I will see if I can fix this before the deadline, but I may need to leave it as it is.
I have noticed a couple of small issues on the processing end (C++ app) of my project as well. One of these issues occurs when a '.' is used in the middle of a sentence (e.g. Mr., Dr., St., etc.). In these cases, the sentence is split into one or more sentences, depending on the amount of periods in the sentence. I believe that this can be resolved by checking for titles (Mr., Mrs., St., etc.) when a '.' is encountered. Another small issue involves '\n' registering as a sentence. This results in sentences appearing as blank lines in the generated text file. This problem can probably be eliminated by a small if clause checking for sentences consisting of only '\n', and not adding them to the sentences file.
Testing of the webpage seems to be going fairly well so far. I have tried feeding a few news articles from online sources to the program, and have been pleased with the results. The program does not seem to slow down at all, and hopefully it will not as I move to bigger and bigger files. This testing has led to the discovery of one other minor bug. If a word appears multiple times in one sentence, the sentence will appear multiple times in the word's list of appearances. I believe that I can fix this bug by comparing sentence indices to ensure that duplicates are not written to the file. This should happen in the C++ application, rather than in the webpage.
In the next few days, I need to create my PowerPoint and figure out what I want to do for my demonstration. Also, in the coming days I will be posting a blog post containing a sort of self-evaluation of my project. There are things I am very pleased with, and there are things that I feel I could have done better. Hopefully this week will finish up well.
In the past week I have made a few minor changes to my project. As of my last update, I believed that hash table size should be roughly equal to 70% the size of the data set that the table will contain. After meeting with Dr. McVey a couple of times, I have learned that because I am using 'chaining' as a means of conflict resolution, the table size should be roughly equal to the size of the data set. To accomplish this, I am using the same means of finding the approximate word count, and then finding the nearest prime number >= to the word count. Hash tables should be of prime size in order to obtain a good distribution throughout the table.
I have also made some minor changes on the webpage portion of my project. Per Dr. Pankratz' suggestion, I have changed the way in which sentences are displayed when a word is clicked on. Instead of displaying all of the sentences in which a word appeared, words that appear in >10 sentences will now display a random sample of 10 sentences in which they appear. Currently this random sampling only occurs once, when the page is loaded. However, this will be altered so that a new random sample will be created each time the word is clicked.
With less than a week remaining until presentations, I need to focus on testing and optimization. The time has passed to add new features, and I'm now focusing on wrapping things up.
Today I made a few fairly significant changes to my project. These changes involve word filtering and hash table size.
I have expanded the list of words that I consider "useless" and wish to filter out. To prevent these words from occupying space in my Hash, I am comparing each word to the list before entering it into the Hash. The word list is saved in a text file, and loaded into a string array, one word at a time. The set of words that I am filtering out were taken from Michael Klosiewski's 2013 project. This set includes about 150 words that do not help provide insight into the content of a file. I have some concerns about comparing each word of a text file to 150 strings (worst case), but it does not seem to be too time consuming at this point. I am considering the alternative of only comparing the top n words from the file to the set of useless words just before writing the results to the file. For now, I have decided to stick with checking each word while reading, to prevent useless words form entering the Hash.
I have also made some changes to my Hash class and its constructors. Previously, Hash's default constructor was using a table size of 10, and there was no explicit constructor. I have written a constructor that accepts an int representing table size. Now, a Hash can be created with a given table size. Dr. McVey and Dr. Pankratz has suggested that a hash table should either be large enough that the data fills 70% of it, or that it is 70% of the size of the data (I can't remember which it is, I will need to check). These changes will allow me to make the Hash the appropriate size, corresponding to the size of the data.
Fittingly, I have also made changes that will allow me to find the size of the data (text file input) before creating the Hash. I have accomplished this by using the stat function and the average size of an English-Language word (Wolfram Alpha says it is 5.1 characters). I have written a function that first uses stat to find the size of the file in bytes, and then divides that size by 6 (I rounded up from 5.1 to account for spaces). This gives us an approximate word count for the text file. This word count is returned to the main function, where it is used to create the Hash. The Hash constructor is sent either (approx. word count * 0.7) or ((10/7) * approx. word count), depending on how large the Hash should be (as explained above).
I have tried out some slightly large input text files, and the program still seems to run pretty quickly. As the samples become larger, I expect it to run somewhat more slowly, but it should not be too sluggish. Adding the more expansive IGNORED_WORDS list seemed to improve the results quite a bit, but I'm sure that I will find more words to add as I continue to try different input text files. I am hoping to focus on cleaning up files and documentation while creating my presentation, seeing as May 1st is drawing near.
After meeting with Dr. Pankratz a couple of times in the past week, I have made some additions to the processing side of my project. I have added a few functions to my code that will drop the suffixes from words and filter out certain words that when alone do not provide any insight to the overall text. These "ignored words" include conjunctions, etc. We hope that by dropping the suffixes, we will be able to obtain the root word from different tenses of that word. I realize that in some cases, the altered word will not match up to its root. For example, if we remove the "-ed" from "sentenced", we are left with "sentenc" which does not match the root word "sentence". We have agreed that in a large text sample, the amount of these situations will be relatively low, and that we can deal with a small amount of missed words. I am now working on building both a list of suffixes and a list of words to ignore. It will take quite a bit of consideration to decide what words I find to be "useless" and which suffixes I think should be dropped. With the deadline drawing close, I hope to finish additions soon and focus primarily on polishing what I have and on large-scale testing.
It's been a while since I have written a blog post, so I have quite a few things to report. I experienced a short period of time over which I did not make much progress on any element of the project. This was due to job searching and spring break. Recently I have been making steady progress, which I hope to maintain all of the way to the end of the presentation and defense.
I have made revisions to both the processing and display sides of my project. On the processing side, I have changed the way in which I read and store sentences. Due to size concerns, I am no longer using an array to store sentences. Instead, I am taking each sentence from the text file and writing them to a 'sentences' file, one per line. This way, I don't need to worry about conserving space as I did when using an array. The 'appearance indices' for each segment will not need to be changed, because they now correspond to line numbers in the new file.
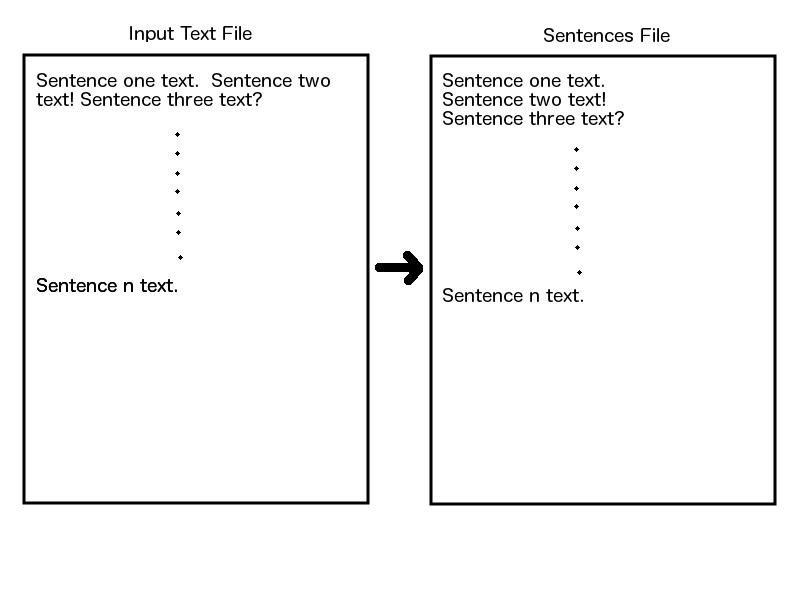
On the display end of the project, I have essentially redone the webpage. I have added some (hopefully) nicely-styled elements, to make the page a little easier on the eyes. I have also changed the layout of the page, so that segments appear on the left, and the associated sentences on the right. I am now happy with the way that the page looks, so hopefully changes from here on out will be minimal. An image of the new design can be seen on the Pictures page.
My current objective is to test the processing end of my project with large samples of text, probally pulled from online sources. Dr. Pankratz suggested pulling tweets from Twitter, so I will probably give that a try soon. Also, I am planning on making a change to the project's terminology, by using 'words' instead of 'segments'. In the beginning of the project, I believed that I would be identifying key words and snippets of text, but I now know that I will only be working with key words. Also, it seems to me that it is easier to use 'words' because it requires little explanation.
After struggling with file reading via JavaScript for hours over the past couple of days, I found out that my difficulties were due to the nature of the Ajax request I was trying to make. The request was perceived as being cross-domain, which requires specific server settings to execute. Because of this, I have decided to do the file reading with PHP instead of JavaScript. Drawing upon the PHP that I had learned in CS 322, I was able to read from a text file an incorporate the data into a simple html page. From here I hope to start passing more data via the text file and make the html look a little nicer. I think that getting the read to work was a pretty big step, and the rest of this part shouldn't be too bad.
Over the weekend, I made a couple of slight changes to fix the issue I was experiencing with reading text files. Dr. Pankratz suggested a fix to prevent a while loop from running one too many times, and it worked well. Today, I added the 'Pictures' page to my website, which took a little bit of extra work due to some difficulties with jQuery.
I am also working on the visualization side of my project. I decided to take a short break from the processing side, and work a little bit on the presentation of the data. I have made a rouge HTML page where the most frequently occuring words will appear, along with JavaScript functions to expand and collapse paragraphs corresponding to each word. I have been having some trouble loading data from a text file with JavaScript/jQuery. I can use jQuery's .get function to get the file's text, but only in Firefox, not in Chrome (my primary browser). I have read that this is due to either a flaw in Chrome or a Chrome feature to prevent access of local files via ajax request. Either way, I need to find a work-around. I will experiment with this more tomorrow, tonight I need to study for CS 370.
I have added a screenshot of my extremely rough visualization page to the 'Pictures' page.
Today I made a couple of small but important modifications to my code.
I had previously been parsing and processing text from a string variable. The program will now read from a .txt file, and parse and process from there. There is one slight problem with reading from file at the moment. Currently, if the file does not end on a new line, the program will read the final character of the text twice. I believe that this has to do with when the program reaches the EOF, but it will require further investigation.
Up to this point, I had been using multiple comparisons to identify special characters, which made for some long if statements. Now, per the suggestion of Dr. McVey and Dr. Pankratz, I have created two arrays - one to identify special characters and one to identify characters that are used to end sentences. At this point, I consider any non-alphabetical character to be a special char, and only {!, ?, .} to be sentence-ending. I can then use the decimal value of any ascii character as an index to either array.
I have yet to do the rigorous testing that I had planned to do on sentence and segment identification, but I plan to do so very soon.
Today I added a couple of functions that allow my program to parse text into sentences, and sentences into words.
The first function that I wrote today takes a sentence as input, creates a Segment from each individual word, and then adds the Segments to the Hash. In the future, this will need to be expanded to create Segments out of phrases, but at this point I felt that words were a good place to start. I believe that it will be difficult to determine what makes up a phrase (i.e., what to look for in the text when parsing), so I will need to think it through for a while before trying to implement it.
The second function takes a block of text and divides it into sentences, building the sentences array up one sentence at a time. Presently I am only processing a string within the function, but soon I will adapt the code to pull the text from a file. I plan to take all of the file's text and concatenate it into one large string before processing. If the string is too large, it can be split up.
I have done some more mild testing on these new features, and they have worked just as I intended. The code that I have now will be at the core of my project, so it is important to thoroughly test it. For this reason I will be taking some time to throw different cases at the program to look for and patch vulnerabilities.
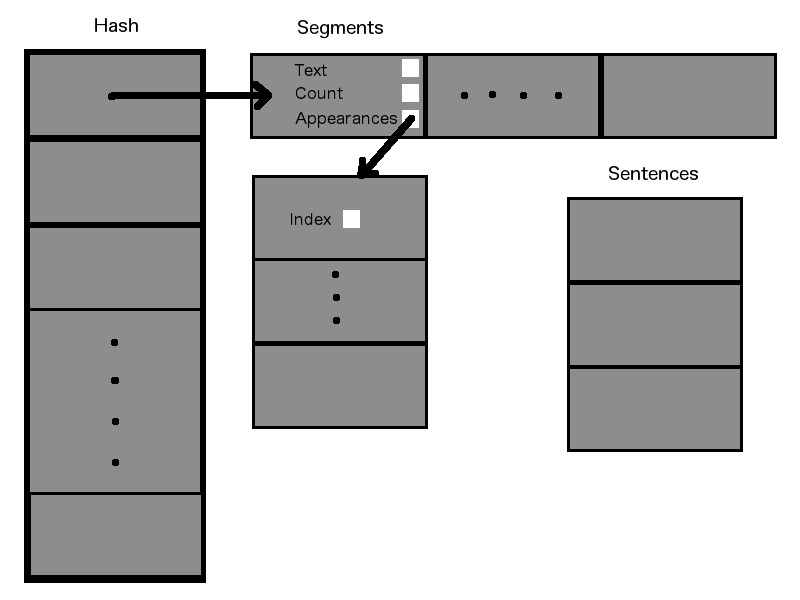
After meeting with Dr. Pankratz on Friday, I had a pretty clear idea of what I wanted to try for the first implementation of my data structures. Today I created two classes which, along with an extra array, will store all of the data I will be working with.
When data is taken from a text file (which it is not quite yet), it will be split up into sentences. Each of these sentences will then be placed into a cell in the "Sentences" array. From here, individual words/phrases from the sentences will be processed and used to fill the major data structures.
The first class I have chosen to call a "Segment". A Segment represents a chunk of text - either a single word or a phrase. The Segment contains data involving the makeup of the string that it represents and where in the overall text that string can be found. To track its use, a Segment contains a pointer to a dynamic integer array, each of which contain an index of the Sentences array. This allows each Segment to keep track of where it was used in the text, in order to be able to provide the context in which the Segment was used.
The second class is essentially a hash-table, which I have named "Hash". The Hash consists of an array of Segment pointers, which point to dynamic arrays of Segments. It uses a hashing function (which I have tentatively written) to determine the index at which to insert each Segment into the Hash. Once an index is determined, the Hash will check to see if the dynamic array at that index already contains an identical Segment. If it does not, the Segment will be inserted into the dynamic array. If it does, the new appearance will be added to the existing Segment's appearances array.
The diagram below is the best that I could produce with the Gimp and the trackpad on my laptop. I hope that it is easy enough to decipher. If you have any questions or comments about the diagram, feel free to contact me. I will try my best to explain things more clearly.
I have only performed some very mild tests on my data structures so far, but things seem to be working nicely. I plan to expand my tests throughout the week, and create some sample files for I/O. Hopefully I will be seeing some encouraging results by next weekend.
Today I finally managed to make my website operational. I had originally created the site using Ruby on Rails, so many of my HTML files contained Ruby (.html.erb files). The Ruby code was not working on the school's server, so I decided to remove all ruby from the project and manually link the files.
I also visited with Dr. Pankratz today to discuss data structures. We tossed around some ideas, trying to figure out the best way to store a large amount of words and phrases, while keeping them easy to access. At this point, I believe that I will be using a hash table in conjunction with an array or linked list to the amount of times a word/phrase appears and where it appears. We will be meeting again on Friday to think this through some more.
Today I continued to expand upon my basic site design. I adjusted the styles of my general page template, created styles for the blog page, and fomatted blog entries. I have also created shells for the resume and gallery pages, and will fill these pages out in the near future. Certain aspects of the site (philosophy, blog, etc.) must be completed by Thursday of next week (2/6/2014), so I will need to focus on writing content for those areas.