THIS IS THE BLOG
Home
Blog
Source Code
Resume
Week 12 April 17rth, 2017 Progress - Completed my mutation function. It produces a new genome based on another genome. I can now produce another generation. - The idea for the crossover function does not seem to be easily implementable, might not do it to have time for presentation preparation and playing with the data to observe algorithm compatibilities. - Implementing minimal UI so that it is more presentable. - While implementing UI, found a problem where if the tag cloud was too small (small amount of words), the clump finder would grow to be the entire thing and get stuck because it is always happy with the clump. Usually it stops once it is unhappy with the clump it has so far. - Decide that number of words must be at least 20 words. - Trying different data sets and preparing the presentation. - Finished the powerpoint for the presentation tomorrow.
Week 11 April 10rth, 2017 Progress - TagCloudGenerator3's clump finding algorithm is funky and doesn't work the way it is supposed to and gives me bad clumps, going to try to start over with TagCloudGenerator4 - Started working on TagCloud4 where, using the algorithm I made, it will find all possible clumps and return the most efficient one. - Can't decide how to return the clump from the clumpfinder as. It currently returns a RectangleF object, but how do I use that to determine which words are in the clump? Should I have the program determine the words fully in the RectangleF? - Visited Dr. Mcvey and Dr. Pancratz. Walked back with an idea about crossover as well as where to "stop" and start preparing for the presentation. - Working on a redraw function to be able to recreate any solution. Randomizing the arrays has came back to bite me in the butt. - I believe that cntArray is to blame. I think it messes up the sizes of the font, because the rectangles are still in the correct location. - I was wrong. The error came from my swapping around arrays in a genome class function. Redraw function works now. - Working on mutate function.
Week 10 April 3rd, 2017 Progress - Still working on clump finding function. (Trying to implement it so that it finds the closest rectangle and expands the clump to include it). - Uploaded source code onto website with short description. - Clump algorithm can find closest words relative to clump, expand so that it includes that word, then look at how "clumped" it is via (areaUsed / totalArea). - Finding "close" words is very funky. It does not always return what seems to be the closest word... - Still tackling the clump finding algorithm over the weekend, slow but steady progress. Still no idea why clump efficiency numbers can get higher than 1... Distance seems to be working most of the time. - Going to start TagCloudGenerator4 where the clump finder goes through all possibilities of each genome to try to get the best clump by maintaining a clump arrays, TagCloudGenerator3 will be happy with any clump - An idea for TagCloudGenerator5 is that, instead of set efficiency rates for the clump, I want to try checking for jumps in efficiencies instead, because by adding an additional word, it is possible to create a much better clump (check a little bit further).
Week 10 March 27th, 2017 Progress - Visited Dr. Pankratz about fitness issue. Received another approach that I'll try implementing. Seems to work great! Will wait to consult about crossovers and mutations. - Setup a roulette (class) for random mutations and/or crossovers. - Work on standardizing the scale for generation zero. It seems to work properly. - Considering the possibility of increasing word size if the there is a lot of white space left. Maybe I can just fit the word to screen later on. - Fitness calculation of each genome seems to work properly. - Met with Dr. McVey and Dr. Pankratz to discuss crossover and mutation in the genetic algorithm. Came out with a solid idea for mutation. - Work on clump(dense area) finding function.
Week 9 March 20th, 2017 Progress - Work on project walkthrough. - Fixed a problem where words with too low of a count value would get a font size of 0 (due to being divided by the scale), which would cause a crash. - Review walkthrough notes. - Sucessfully created a genome class and a sample of generation zero, still working on determining the fitness of each genome. - Fixed a problem where the total recArea was giving numbers that were way too big. - Work on determining the canvas size for the genentic algorithm (taking the largest height and width of each genome). - STUCK due to problem: all my genomes have the same fitness because all the word sizes in the different genomes are the same, and I use whitespace to determine fitness. I need word sizes to be the same so that crossovers can work properly.
Week 8 March 13th, 2017 Progress - Spring break. San Francisco took away a week's worth of progress. - Will try to catch up ASAP starting with generation zero.
Week 7 March 6th, 2017 Progress - Visited Dr.Pankratz for ideas about genetic algorithm, prompted to record data for analysis purposes (to come up with ideas). - Visited Dr.Pankratz and Dr.McVey to explore how I might approach developing the genetic algorithm. - Going to start by creating a stronger generation zero. - Adjusted so that initial rectangles do not collide immediately with existing rectangles.
Week 6 February 27th, 2017 Progress - Work on creating certain rectangles for words with different frequencies. - Visited Dr.McVey for collision detection advice. - Collision detection works, as well as making sure rectangles never go off screen. - I need to make the program able to size them up to fill in white space appropriately, or size them down to make space for more words. Going to calculate display area, then use total rectangle area to subtract from it. - Sucessfully randomly generated a tag cloud of 100 words.
Week 5 February 20th, 2017 Progress - Found and read an interesting chapter concerning the generation of tag clouds by Jonathan Feinberg, person who developed Wordle. - Found, explored, and read articles from ai-junkie, a website written by textbook author Mat Buckland. - TO DO: ask prof about filter problems(check), ask about having a genetic algorithm fit words into preset shapes..., fitting in words in ANY whitespace. - input bunch of text instead of selecting sources, something "more" to do. - filter user selected word from tag/word cloud. - source filter, different sources, different colors/fonts? - clicks produce stats, imgs, context? - It seems like the question marks might have been caused by different languages from twitter. - Learned about encoding, decoding, and deciding on a fitness function. - Looked at vega grammar website, but I am leaning towards just using C#. - Read about using Linq to "increased readability, reduced complexity, and shorten code. All these at the price of an ignorable insignificant performance drawback...", but decided against it. - Started experimenting with drawing words on a windows forms application. - Got stuck with figuring out how to determine the coordinates of the drawn words, visited Dr.McVey and came out with an alternate function that used a rectangle object as a parameter. - Made one program write heap content to file, and the windows form application to read heap content for display. - Started working on application GUI, namely adding an exit and minimizing button(it starts up fullscreen).
Week 4 February 13th, 2017 Progress - Visited Dr.McVey, fixed my heap error (I did not check both children before swap). - Started working on filtering unwanted tokens; looking at David Ferris' project. - Compiling a list of "stop words" to filter out, as well as methods to streamline certain things such as uppercase/lowercase & punctuation. - Implementing the filter of my unwanted words and characters, as well as making all words uppercase for consistency. - Filter is working, but there seems to be a weird problem where words made up of question marks get through the filter (will ask a professor). - Continue to test sources to add words that will refine the filter. - Made a list of suggestions given from classmates and professors in class.
Week 3 February 6th, 2017 Progress - Visited Dr.McVey, will try to use a heap to get top "n" from the hash table. - Will look into 2014 project to learn about filtering out unwanted tokens. - During discussion, Dannie brought up the visualizing language VEGA that might be of use when creating the tag cloud. - Got my gantt chart up (very primitive looking). - Found a source to study and research genetic algorithms (Mat Buckland's ai junkie). - Rethinking the design for data structures and how I am implementing the heap to organize data. - Visited Dr.McVey about "clicking on single words in tag cloud to get another tag cloud" functionality.
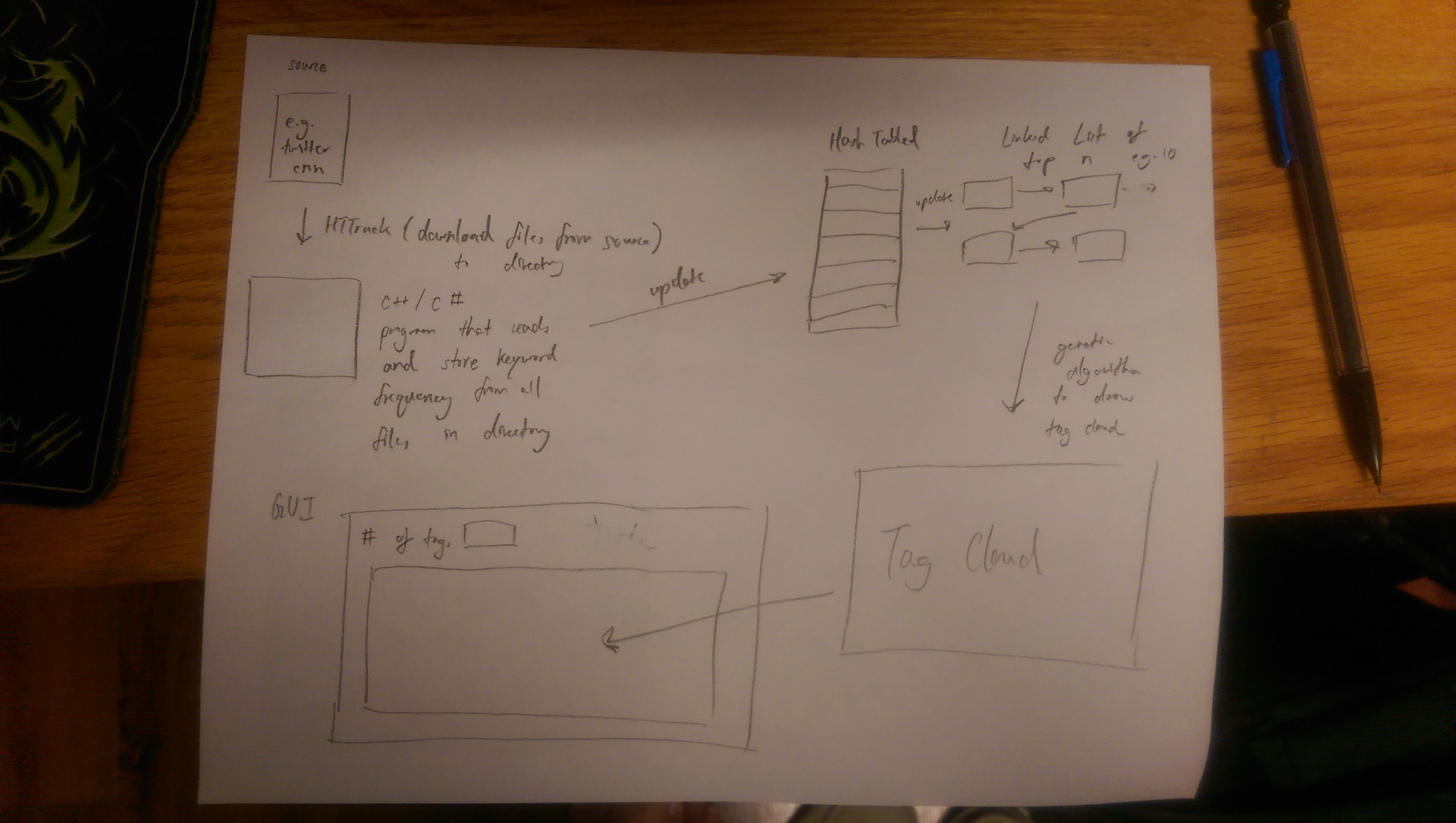
Week 2 January 31st, 2017 Progress - Visited Dr.McVey and Dr.Pankratz for guidance and opinions concerning the use of HTTrack. It seems promising, but I was told to start working on the actual parsing and organizing of data. - Will be looking into methods and the like in C++ and C# to read all files in a particular directory in compsci02. - Wrote a philosophy statement, updated my resume, and put them on the website. - Successfully read through all the files in a directory (without doing anything with the data), will be trying to only work with data that matters - Hashed every "token" and kept count of each word's frequency (did not filter out junk yet).
Week 1 January 26th, 2017 Progress - I got the website and blog up and running. It has a homepage that contains next to nothing, and a blog page that will hold my blogs. *this* - I have divided the project into smaller sub-tasks. - I have looked at past iterations of the project(2014 and 2015), and will be exploring using php to retrieve data from a source. update: since I would like the application to be general, I will not be pursuing a twitter api path - I have decided that my first task will be to figure out how to retrieve and organize the data. - Did some research to come up with potential ways to implement the program >> web crawlers, using hash tables and linked lists to store data, what genetic algorithms are, etc. - HTTrack seems like a good way to download all the files to be parsed from a particular source. It is software used to configure and download desirable files from any website e.g. .html, .js, gifs, etc - Exploring what the boost library for c++ is and how it might help with reading multiple files to store data. Should I use it?