WEEK 14
LAST WEEK and GRADUATION ON THE WEEKEND! WOHOO, I really enjoyed this last semester. I am appreciate Dr. Diederich guidance throughout my research project.
Now I need to finish up my documentation for my project and get my 3 ring binder together/flash drive in for final turn-ins before graduation.
I had my code defense last week with Dr. Diederich and Dr. McVey. They gave me create insights on how to make my project even better around the conversation of sentiment analysis.
WEEK 13
PRESENTATION WEEK! I met with Dr. Diederich and Dr. McVey earlier in the week to go over last minute changes I need to make on my project before presenting on Thursday.
Once I made those changes, I started to work on my capstone presentation by organizing it into slides that made sense for users and viewers to visually see. It was important for me to practice my presentation a couple times to be organized in my thoughts of how I want my presentation to go.
After the presentation, I was relieved and full of gratitude to present in front of a lot of great people. What a great semester it was! Only one more week!
WEEK 12
[SCRAPELY] compsci04 testing on multiple devices.
I have some pretty good sentiment analysis working with the library Text Blob. I really need to organize it a bit better. I was talking with Dr. Diederich today about my next steps and it will be getting my graphs more organized for sure. On top of that have a text box updated on UI telling the user on how many pages have been scraped at this time. I want also relevant data for businesses, so I am going to figure out on how to put restrictions on reviews only back until 2020 because 3 years is a good number to stop. I also need to figure out how to embed multiple graphs into my html code. I also want to give users an understanding of what is going on in the graphs so it’s both Data visualization and a learning tool.
SOME EXAMPLES BELOW
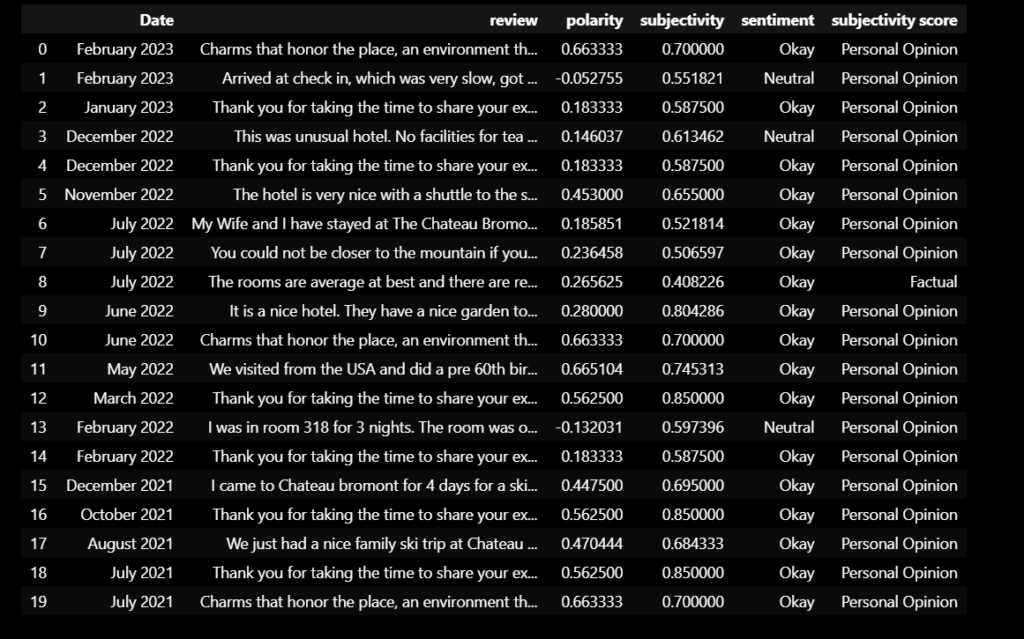
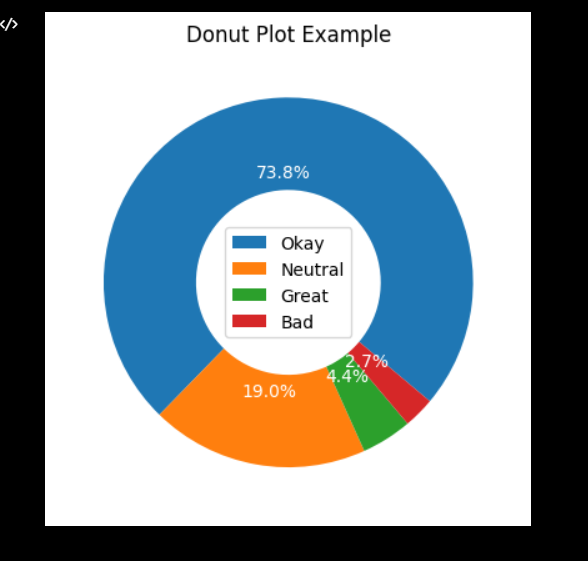
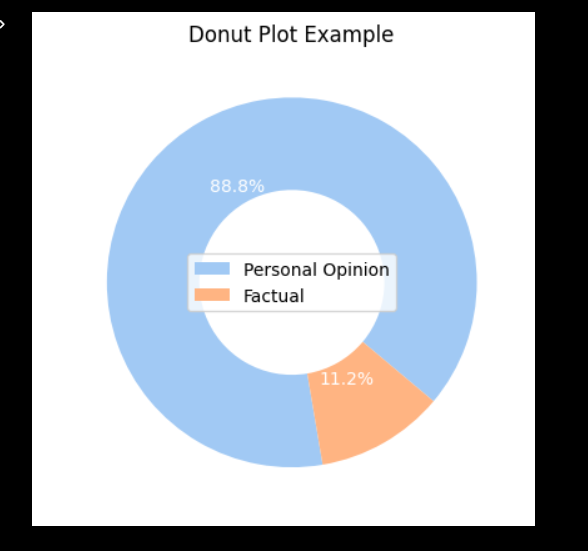
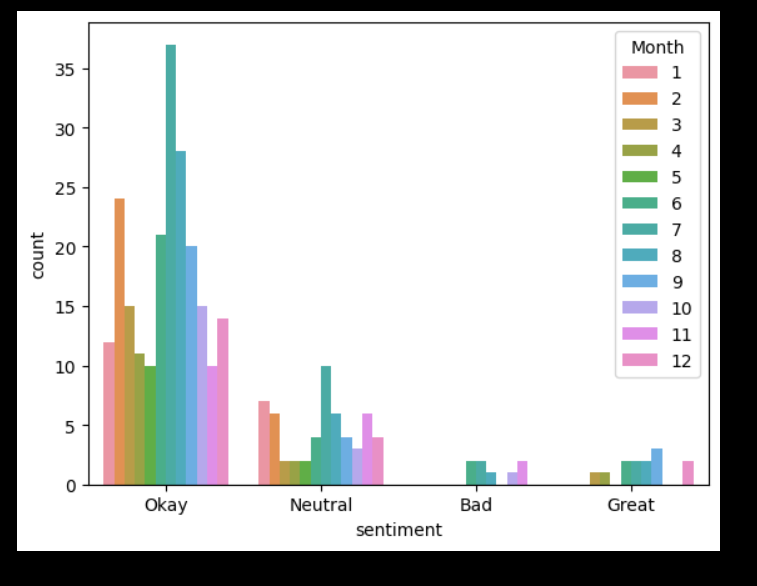
WEEK 11
WEEK 11 I was getting back from Easter Break on Tuesday and trying to come up with a plan with my professors instead of using a progress bar I should be just having a bar updating on how may reviews of been scraped on each page. Which is a great indicator to tell the users where things are at in the process.
When it comes to the seeing the dates of each review, I talked with Dr. Diederich about this. He suggested that even if there are no dates you can just say ” no date available”.
WEEK 10
Week 10 I am trying to come with with a plan with Dr. Diederich and Dr. McVey around how I can come with a progress bar. Still continue to research and understand how I am going to do sentiment analysis. I am going to be honest here, I am pretty nervous because there is so much to do with it. Updates to follow..
WEEK 9
I got a lot of insights from Dr. Diederich and Dr. McVey on how to move forward in the last weeks of my project. I going to use either text blob or VADER libraries to help me with sentiment analysis. The feedback I got was very useful. They are :
Have dates be the limiting factor rather than the number of pages, or restrict the info given to the client to just the years that are relevant. On the requests page, have a place for clients to tell you which years are most relevant.
Make a progress bar to track when each page is finished scraping. Also change it so that when each page is finished the client is notified.
WEEK 8
Had a couple good meetings with Dr. Diederich around next steps for visualization that can be meaningful for businesses to look at. We are both thinking more about Sentiment analysis and intent analysis. Have a good amount of research to do on this before I can move forward with next steps.
Spring Break
HAVE MY MATPOTLIB AND SEABORN WORKING WITH THE DATA THAT SCRAPED!!!!! Definitely, a new learning experience for me. Had to look at many tutorials around both Matpotlib and seaborn to be able to figure out how to do it.
FINALLY! Got my python code to scrape the data from url and create a csv file in my folder with all the reviews!!! IM PUMPED…..unfortunately still not getting the data to the scraped html page. I am just happy that it is finally taking the users input from my index.html page! Progress! LETS GO.
My next tasks are getting the data to show up on scraped html page and then start messing around with Matplotlib tutorials and understand on how they work.
WEEK 7
Still working on getting Flask completely through to my hmtl files…..still coming up with errors. Meeting with Dr. Diederich to go over some of the issues.
3/10
Meet with Dr. Diederich and the error is gone but the python file is not creating the csv file and not getting to my scraped html page. Hopefully make some real progress over spring break.
WEEK 6
I have finally got my flask working with my python and HTML the problem now is that every time I hit the scrape button on my html page it is bringing me to C drive index page with a ton of files saved on my laptop on the csv file I want it to bring up. Talking with Jadon this week on how he is doing with the flask application. I WANT TO GET THIS PART DONE BY THE MIDDLE OF THE WEEK!
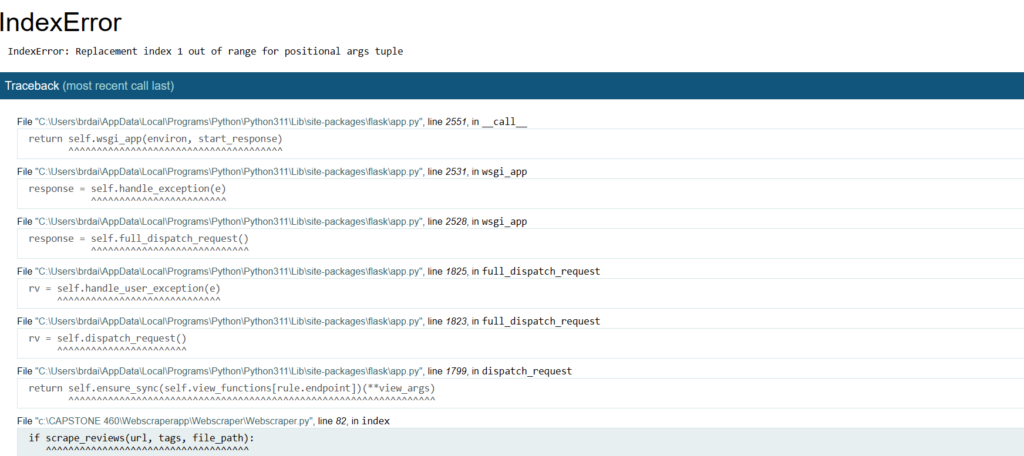
FLASK IS WORKING, very excited about this….but still working through some things such as it connects to my index.html but when trying to scrape a website it takes me to an error page. SEE BELOW…..working through and a little be frustrating to be honest.
WEEK 5
2/27/2023
I’ve continued to try to hook up my python code to the html website. I have tested it a few times with Visual Studio Code. I’ve made a couple files now. I have a web scraper.py which scrapes the website. I have a file called app.py which works to connect to the website with Flask. I have created a result.html which will display the web scraping data. I am still working through some bugs. Updates to follow this week.
WEEK 4
2/20/2023
Working on connecting my python scraping code to html front end page..updates to follow this week.
WEEK 3
2/12/2023
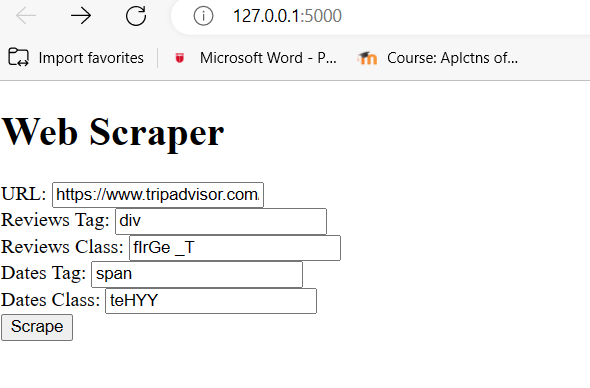
I have gotten some guidance when our class had the opportunity to get different opinions from other classmates and professors. They gave me some good ideas on how to approach the next steps for the project. Right now, I took a little break from web scraping because I was getting stuck on being able to scrap the data in bigger quantities that I would like……so I decided to make the front design on what my website would potential look like in html.
This website will allow user to plug in the URL of their choice and the tags they are looking to scrape.
Now that I have this completed…..my next steps are figuring out to scrape bigger quantities and researching ways to present that data on the backend. To connect these two applications to the HTML I will have to use this tool called flask to hook up the python code to it. A couple classmates of mine recommended it.
02/16/2023
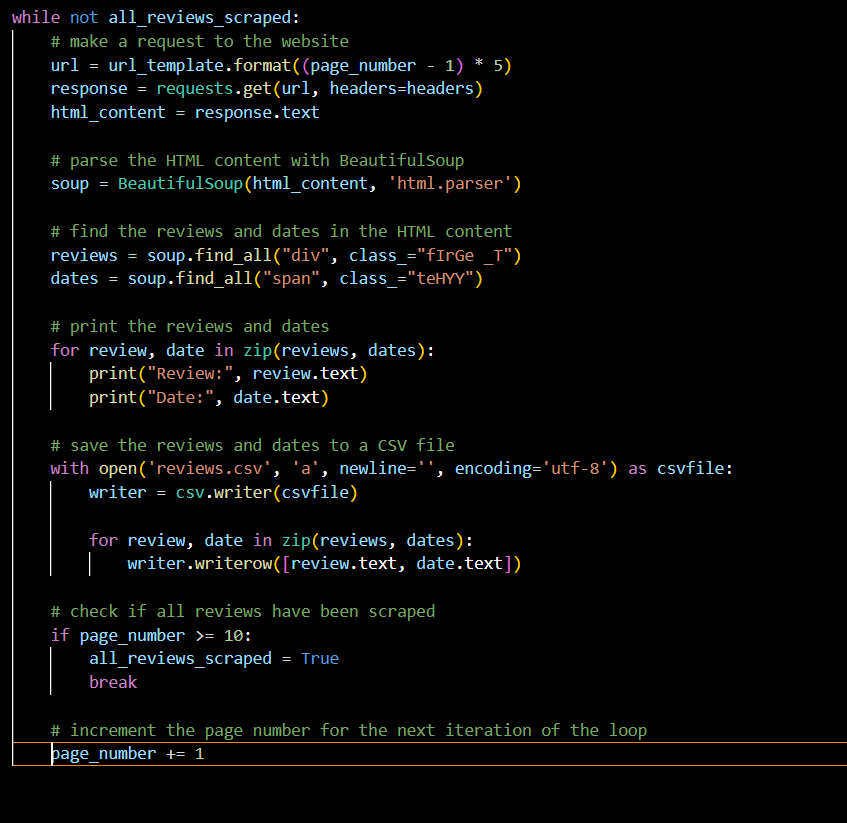
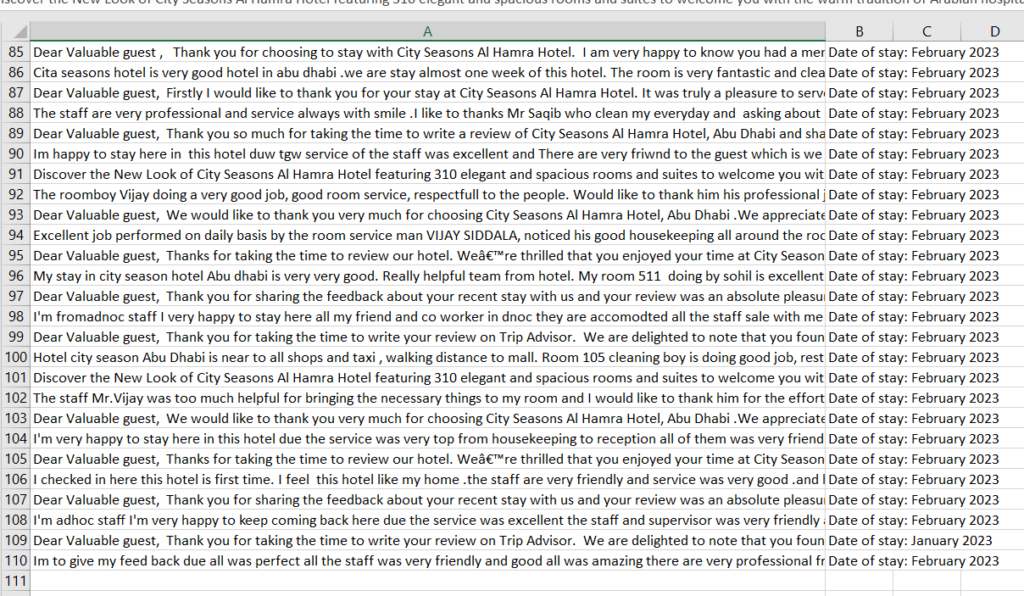
I am pretty pumped up tonight because I able to pull all the reviews from the Trip Advisor and also put them all in CSV organized. I was using a while loop and it kept pulling in the 7 same reviews over, over, over …………again. Very frustrating because I thought I made some great progress. Until tonight!!! Wohoooo, instead of doing a while true loop I decided to do a while not loop (called all_reviews_scraped and set it to FALSE so the loop can begin) and breaking once those tags are no longer on the site and it worked well! I also needed to define a variable called page numbers and set it to 1 at the beginning of the loop. Then, for each iteration of the loop, it will scrape the reviews on the current page and increment the page number variable. Once page number reaches 11, it will set all_reviews_scraped to TRUE and break out of the while loop.
WEEK 2
2/2/2023
I met with Dr. Diederich today around next steps have being able to pull bigger data from websites. Right now the basic stuff is easy to pull but the next steps is getting more data pulled from sites like Amazon, EBay, etc. Where I got stuck is when I was trying to figure what is the right data to pull when you right click and hit inspect.
Next steps are pulling more data to make sure my code can work in any scenario. So first pull a lot of data and then trim as I go, to get the right data I am looking for.
He also suggests that my code right now is making me manually put in what I want to pull from different websites. I am going to continue to figure out a way to be able to pull specific data from any site based on criteria such Name, Review, etc…
2/7/2023
I have finally figured out to pull the data I am looking from a site like Trip Advisor …..still needs some cleaning up but starting to come along. Here is the code I have developed to get this data.
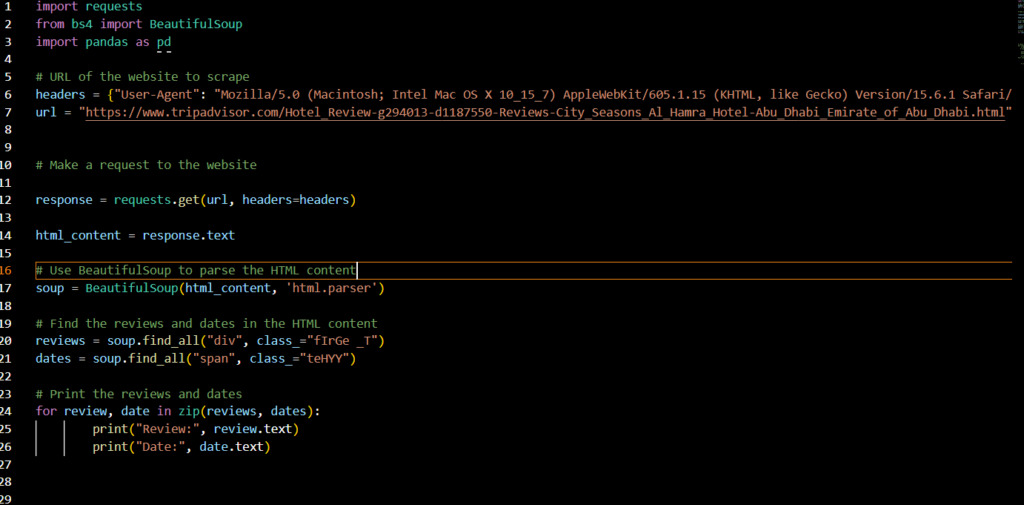
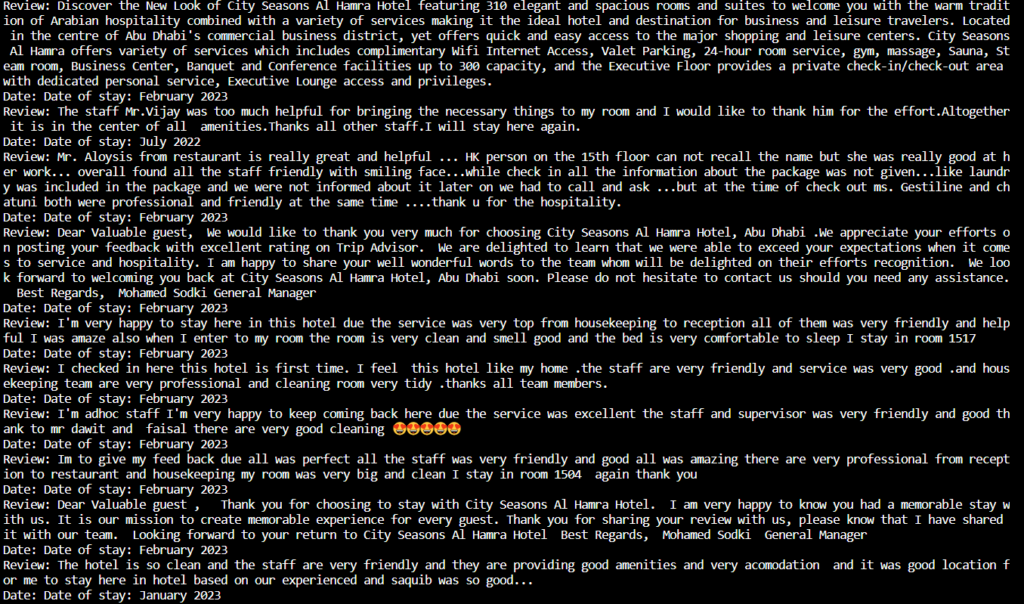
For a good week, I couldn’t figure out why I couldn’t access the website and pull the data. I thought I did not have the right libraries installed or my computer couldn’t handle the tasks. I figured out that I needed to have a USER AGENT to access it. It also was a little bit of a challenge to be able to figure out the right data to pull from the Trip Advisor html page.
WEEK 1
1/30/2023
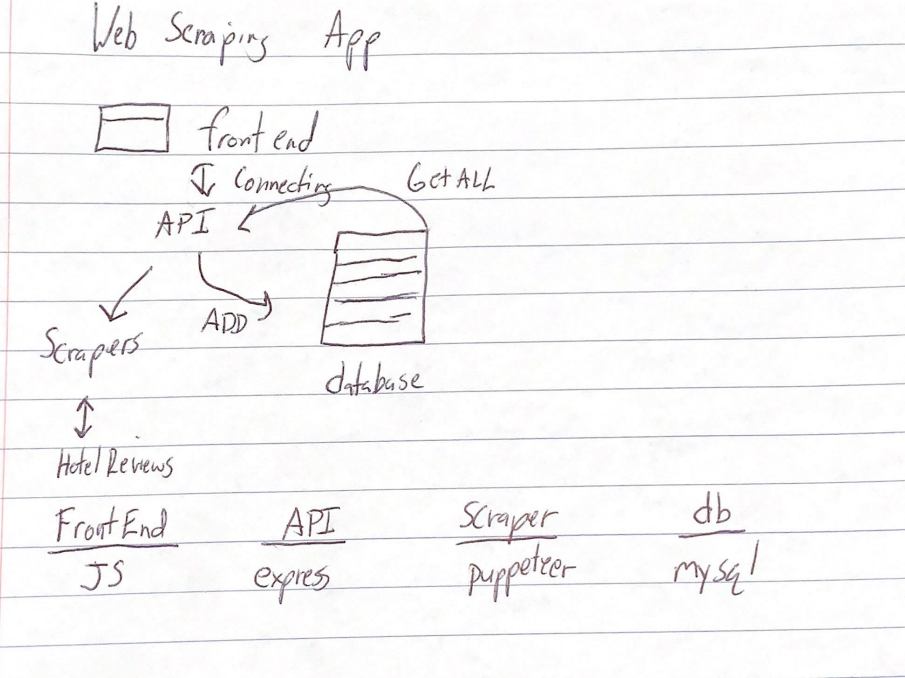
You are looking for me to create a website where you can get reviews and ratings on the best hotels out there. So, all the reviews on this site will be able to be displayed and shown on my website. I will have different colors and sizes on the data based on if the reviews are good, bad, or mediocre. This site will be easy to use for even older people. I have already been researching the best practices to make a website like this. I think it will be best to break up the website into four parts. Front end (JS), compsci04, Scraper (puppeteer), and DB (MySQL). I want to be able to also search for keywords around hotels such as “two beds” or “one bed.” I think some of my research will be about talking to people about what they look for when they are searching for a hotel. Maybe things such as bathroom sizes, is there a kitchen, how long can you stay etc.
I have started my website; it is very generic at the moment. I have experience working with html websites from the two classes I have taken in the past (CSCI 330, 345). It shouldn’t be an issue getting this website to run.
My goal is to have my project website on knight domains but have a link to my website that will be scrapping in html.
HERE IS MY FIRST DESIGN:
2/1/2023
After meeting with Dr. Diederich, I have a better understanding of the steps I need to take.
- First step is definitely understanding how to scrape the data from the website. I am more comfortable with JavaScript, so I started researching how it work in that language. I later figured out that python might be the better answer because of all its advanced libraries. I also downloaded Juypter Notebook which I researched and talked to Dr. Diederich about. Juypter keeps the data cleaner to read for me. I have figured out a few ways to do that so far with simple scraping test sites. I was able to pull the authors and their quotes from a page like so….
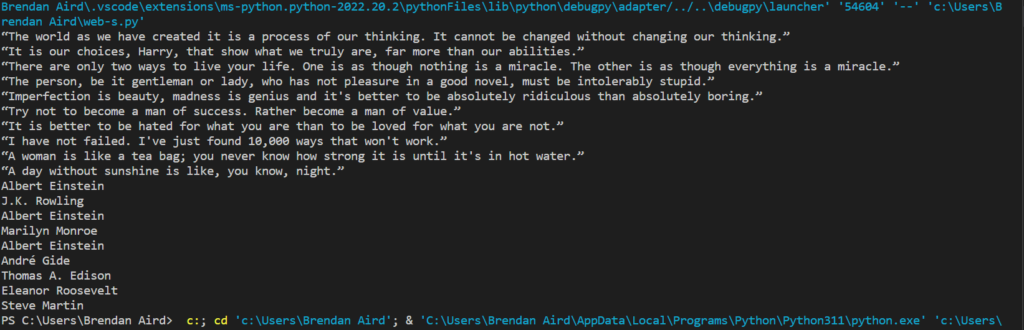
I was able to organize it a step further with having quotes then follow it by have the author right after.
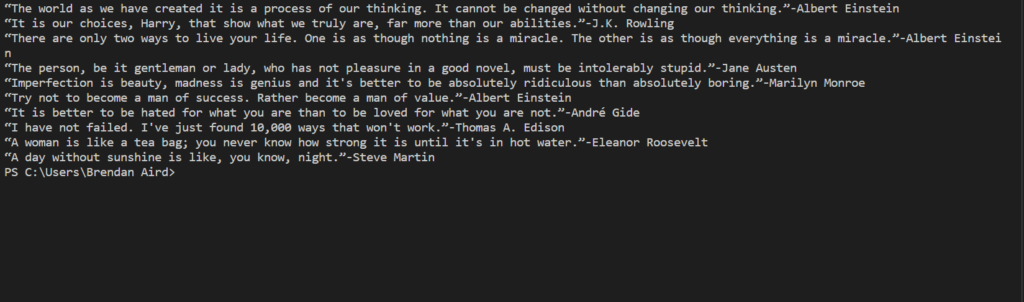
This was the code that executed this output. Fairly simple at moment.
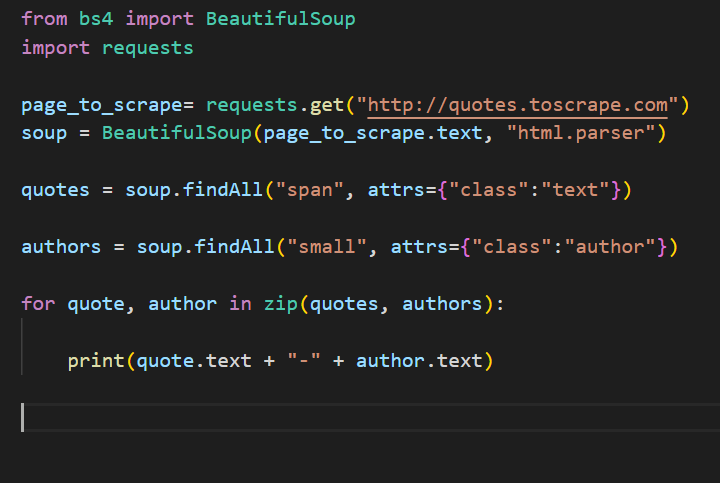
Here is what this code is pulling in. Now that I have pulled the right data, I am working on two things: pulling more reviews and dates from other pages on that specific hotel and I am trying to export this data into an excel file to make it easier to look at. Right now, it isn’t the data in the excel file like I will like it to. Stay Tuned