Blog
May 10, 2015
I've done my presentation, had my defense, and made all of the final touches to the website. All of the source code is up, as well as a document of how to use everything. I still can't believe that everything's done. I'm really happy with how everything turned out and can't believe the semester is over already.
April 19, 2015
I made a lot more progress this week and I think I'm almost done! I made my final changes to the PHP script. I have successfully excluded retweets, which helps a lot. Previously, I thought that I had handled line breaks within tweets, but there were still a handful that came through. Now, after some minor tweaks and several tests, I'm confident that they won't show up. Instead of handling them, I chose to ignore any tweets with line breaks because it makes everything easier later when trying to process data. I also changed the script to output three files, instead of one. The first is the same file it's always been generating. The second is a modified version of the first file that excludes all punctuation in tweets to make it easier to handle in the C++ application. I had been having issues where the same words would be counted as different words just because there was a period was tacked on the end. Now, that I don't have any punctuation, it should be more accurate. I still have the original file of all the tweets which I can use for displaying in the C# application. The third file is a informational file that contains the word searched on and the number of tweets it found, as well as some other general information. This way, I can open the file in C++ and make sure to not count the searched on word/hashtag as one of the top results. I can also use this information in the C# application to give more context to what was searched.
I made a few changes to the C++ application. I made this application also write to the general information file so I could help to give more context in the C# application. It has the earliest/latest dates of the tweets, how many unique users had used the word/hashtag, and several other pieces of data. I also made sure that I was catching all instances of non-ascii values in words and hashtags. I kept running into problems because people will tweet using emojis and other non-ascii values, which causes lots of problems in the C++ application.
The C# application is nearly finished. It correctly reads and displays all the information. I fixed the issue that I was running into last week and have stopped the program from crashing. When it picked random tweets to display, it would crash if it had chosen the same tweet twice. I've modified the code so that if a tweet has already been chosen, a new tweet is picked that has not already been chosen. However, now it's throwing errors randomly in another place. I'm not sure why because it throws an exception, I can click continue and ignore it, do the exact same thing again and have it work perfectly.
Over the next week, I want to solve the issue in C#. Once that is fixed, I just want to do a bit more testing and then it should be done! Then I just have to work on the actual presentation.
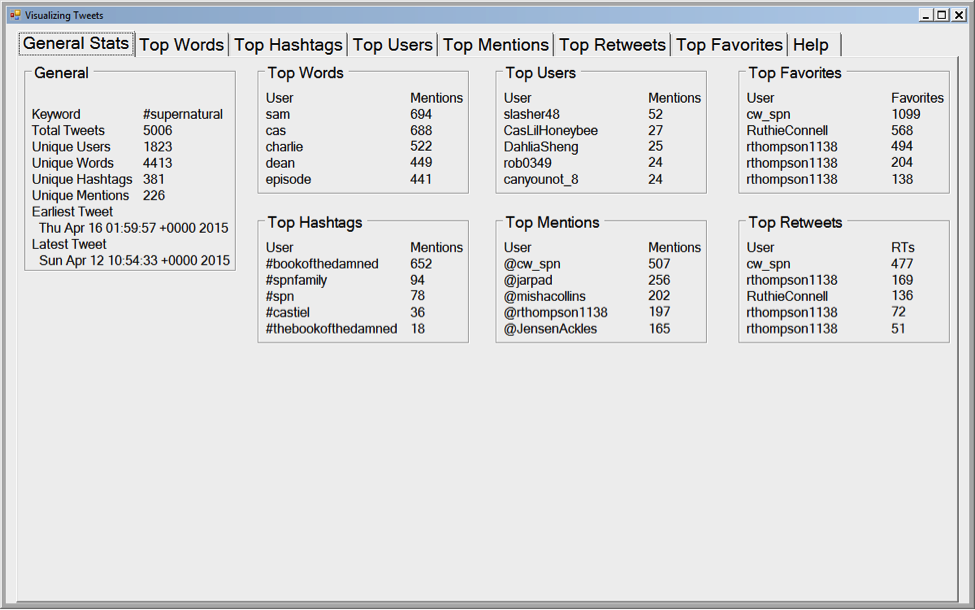
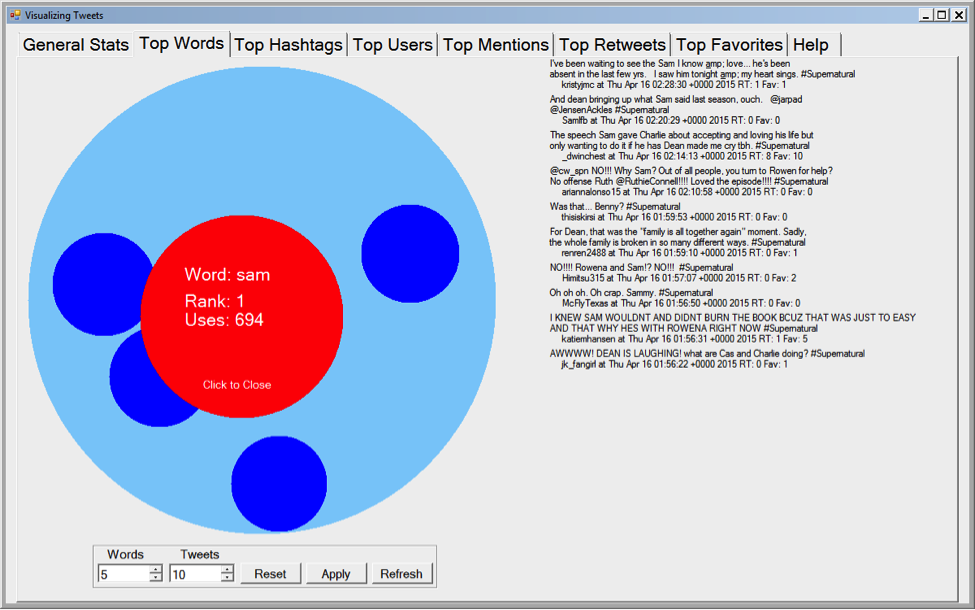
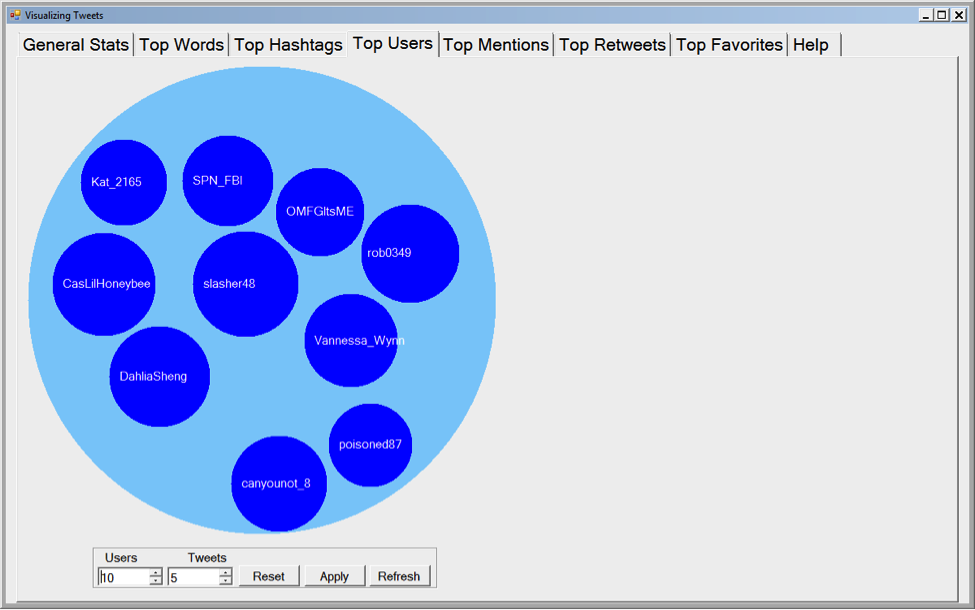
I've put some screenshots of the C# application below. The first screen is the general information tab and is what users will see when they first open the application. The second screen is what the user will see when they click on one of the blue circles. The third is what the use will see when they switch to a different tab.
April 12, 2015
I didn't get a chance to work on my project much during the week, but between yesterday and today, I made a lot of progress. I've spent most of my time working on the visual portion since that has the most work left. I changed it slightly, to make the window a fixed size. It's making everything a lot easier because there are a lot less calculations to do, so I can set the locations of almost everything before run time. I figure that if I have time, I can go back and change things, but right now I still have so much to do. All of the information is still displayed, so I'm not too concerned about it right now.
I also did a ton of set up work, by adding all of the labels and controls and setting the appropriate properties. I also have it set up so it grabs all of the information from the appropriate file and correctly displays the top words, hashtags, etc. I'm currently working on displaying random tweets associated with the top word. Right now, it's crashing randomly and I can't seem to figure out why. Half of the time it works great and the other half it crashes. Once I get it displaying random tweets for the top words, I can copy and paste the code and make a few minor changes to get it to work for the top hashtags, users, and mentions.
My major goal over the upcoming week is to finish the visual portion. The biggest issue is definitely the crashing, but once I figure that out, I should be just about done with the visual portion. There are lots of little things that I would like to implement, but the majority of the functionality should be there once I work out why the program is crashing unpredictably.
Also, if I have time, I want to modify my PHP script one more time. I want to run on a smaller text file. Currently, I'm running into issues with very large text files in the C++ application. I want to modify the PHP script so that it excludes retweets. I already discard them in the C++ application, so it would be nicer if I didn't have them in the file at all. So, I would have the same data, just in a smaller text file.
April 7, 2015
Last week I made one minor change to the PHP script and it's running even faster, which is fantastic. I wouldn't have necessarily needed to make the change, but now I can get several thousand tweets in less than an half hour. This should help testing because as I run the text file through the C++ algorithm, I keep finding little things that are causing problems. With more tweets, and different files of tweets, I should be able to get to a point where I've caught everything.
I also talked to Dr. McVey about some of the issues I've been running into when I'm trying to display tweets in the C# application. I've got it set up so I can very easily select 15 random line numbers for specific tweets (for example, it will display 15 random tweets with the top word when you click on the top word). Now, I just have to access the tweets that correspond with the line numbers. We talked about cutting down the size of the file, which I think will definitely have to do.
I didn't get much else done last week, since I was gone to Phoenix to visit my family over the long weekend. Over the next week, I want to put the finishing touches on the C++ application. I also hope to make significant progress on the visual portion of the project since there is still a lot of work to be done on that.
March 29, 2015
I've made a lot of process since I last updated. I've made several changes to the PHP script, the most important being how fast it can retrieve information. I ran the script earlier this week and it was getting approximately 1000 tweets per hour. I did a bit more research on Twitter's rate limits and was able to make it so that I'm now getting approximately 4000 tweets per hour, which is a huge improvement.
I've also just about finished the algorithm to analyze all of the data. It's correctly parsing and sorting the data. Right now, I'm just trying to find a better way to make the output files. Currently, it will write the top 15 words to a file and then list all of the instances of the word underneath. So the file would have 15 words, one on each line, and then 15 more lines with numbers that are comma delimited that refer to which line the word is in in the file. I'm trying to find a way that will make it easy to access in the C# application for all of the visuals. I've tried writing the instances of the word to its own file, so that the file is just a list of numbers, but when I did this, I running into all kinds of issues when I ran the program on a large set of tweets. I'm still trying to figure out the best way to do this.
Finally, I did a bit of work on the visual portion of my project. I changed the design slightly, so instead of having a menu bar across the top, users can click between tabs to get the information they want. I've also started working on the code to import all the data from the text files. I haven't done a ton of this
During the next week, I hope to figure out some kind of solution to the C++ algorithm. If I have time, I want to get some more work done on the visual aspect.
March 15, 2015
I did a bit of work on the algorithm. I started working witha small set of data, just so I can make sure that everything is functioning correctly. So far, it looks good and everything seems to be working like I expected. I still have to work on creating an output file, or files, so that I can get all of the data for the visual part. I also still need to make sure that this is going to run efficiently when I switch over and start working with larger sets of data.
I've also done some work on the PHP script that will gather all of the information from Twitter. For the most part it seems to be working and I can get the necessary information from Twitter and write it to a text file. Currently, I'm trying to get it set up so that it will keep getting the most recent data. However, I'm running into problems because it will get some tweets multiple times since it always grabs the most recent tweets. Through experimentation this afternoon, I've found out that I can set it up so that it will grab tweets in reverse chronological order (that is, it gets the most recent and then goes farther and farther back). This won't get the most recent tweets, like I wanted, but it will be more accurate because this will eliminate duplicate tweets. So instead of being able to let the script run for 4 days and getting all of the tweets during those four days, you could let it run for an hour and it would get as many tweets as it could from before you started running the script. Basically, after something happened, you would have to run the script to get all of the information about it. If I can't figure out how to get recent tweets, I may go with this second option where you let the script run after something has happened.
Over the next week, I hope to make more progress on the analysis algorithm, specifically working on the output file and testing it on slightly larger data sets. I'm also hoping to work a little bit more with the PHP script so that I can get more recent tweets.
March 8, 2015
This week, I got my php code to run. I was able to set up a personal webserver on my computer. I got my code moved over and everything seemed to run perfectly. However, this code was just a test to make sure it was accurately retrieving informatio from Twitter, so over the next week or two, I hope to refine that more so I can get the data I need saved to a file that I will be able to use in my application.
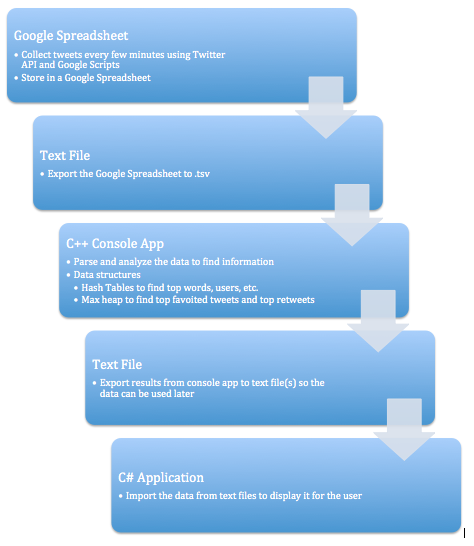
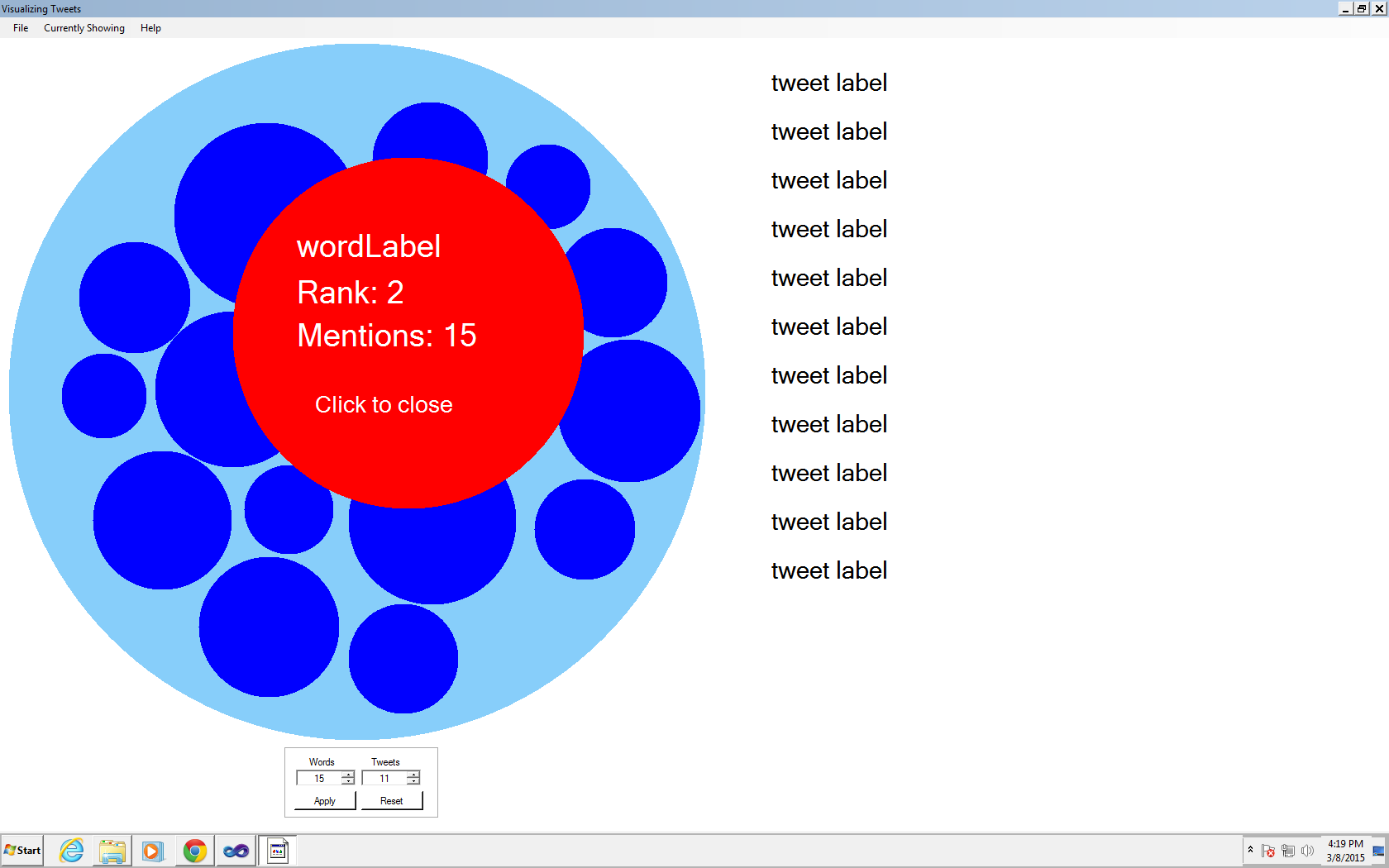
I also made a lot of progress with the visual part of my project. I did some work on some of the sizing issues I was having previously. I also got it set up so that when you click on a word, a larger circle pops up with some statistics and general information. I also have it so the placeholder labels for all the tweets working properly. I also realized that even though there is a lot of data, such as the top retweets, top favorites, top users, and top words, I should be able to use the same code, just changing the labels so that the correct information will be displayed, which will definitely help a lot. I've put some screen shots of the application at the end of this post. I've also included a flow chart to show the order as wella s to how everything should work together.
I made a few changes to the color scheme of my website, since I wasn't quite happy with the scheme I had initially chosen. It's not a major change, but I figured I'd still note it.
In the upcoming week, I hope to do some work with gathering data from Twitter, as well as processing that data to find the top words.

March 1, 2015
It was a fantastic week! I got some of the issues worked out with the circle sizes for the user interface. I had adjusted the circles for the height and width of the screen, but I forgot to take the font size into account. Adjusting the font size seemed to fix that issue. I still have to adjust for the length of the word since words that get to be more than 4 or 5 letters make the circles look strange.
More importantly, I got something going with Twitter. I found a tutorial online that came with a link to a Google Spreadsheet. I was able to use that to export tweets to that spreadsheet, so now I at least have something to work with. Being able to visualize what I would be sending in to get analyzed has helped a lot since I can get a much better idea of the work that will have to be done. However, the spreadsheet brings back a lot of information, most of which I could use, so I'm trying to find easy ways to use that. For example, it returns the number of retweets or favorites a tweet gets. I want to be able to use that information to provide users with the top retweets or favorited tweets containing the word that was searched on.
In the upcoming week, I hope to edit the script in the Google Spreadsheet so that it returns the information in a way that's easier for me to use. Currently, it has additional and unnecessary hyperlinks as well as some information that I do not need. I also hope to make some more progress with the console application that will analyze the information gathered from Twitter.
February 22, 2015
I didn't make as much progress as I wanted to this week, partially because of several computer issues. However, I still made some progress. The biggest thing is the user interface. Last week, I had a interface that worked, but that I wasn't entirely happy with. After a few hours today, I have something that not only works, but something that I'm also much happier with. I've chosen to represent the words in circles of varying sizes, where the larger circles represent words that appear most often. There's still a few bugs, including the size of the word affecting the circle. If words are too long or too short, they look strange when they are presented on the screen, but I think a few simple code changes should fix that issue.
There's still several other things that need to be implemented with the user interface, but I at least have a start. There's also the issue of the interface presenting itself differently on other screens. I did most of my work in the library and everything looked great, but when I moved to my personal computer, it looked really bad. Hopefully, I can get that fixed soon.
I haven't made much progress with connecting to Twitter, but I'm still working at it. I was getting really frustrated with that, so I chose to instead spend some time on the interface.
Over the next week, I hope to get the user interface implementation finished and to make some progress with connecting to Twitter.
February 15, 2015
After another chat with Dr. Pankratz, I've slightly changed directions. Instead of focusing just on text documents, I'm going to try and focus more on integrating with Twitter. Today, I registered my app with Twitter and started to try and work with the PHP to actually get the data from Twitter. So far, it doesn't seem to be working, but I'm still trying to research and figure out what's going on.
I've also started doing some work on the user interface. I've done the basic design and started some implementation. Hopefully this way, once I get the information from Twitter, I will just have to change a few variables.
February 8, 2015
I started looking deeper into projects from last year. Since the goal of this project is to not only analyze a file, but to be able to work efficiently with large text files, I decided to run the code using War and Peace. It ran for over 20 minutes before I finally decided to stop it. After looking at the code more, I realized that the text file is being read three separate times. Also, it's being read character by character, which is not efficient for large text files. I talked with Dr. McVey and Dr. Pankratz to get some ideas as to how to improve this. Instead of reading character by character, we talked about reading a block of text at a time and then parsing that block into words, not really caring if the last word is chopped off because in a very large data file, being off by one doesn't really matter. I've started to test out these features to get a better feel as to how they will work in my program.
January 31, 2015
I was assigned my project this week. I've spent most of the week developing my website and getting it up and running. I've also started to look at previous projects to get some ideas on where to start. It looks like I should at least be able to build off of the algorithms developed by former students.