May 2, 2016
I've paid my dues
Time after time.
I've done my sentence
But committed no crime.
And bad mistakes --
I've made a few.
I've had my share of sand kicked in my face
But I've come through
(And I need just go on and on, and on, and on)...
Queen, "We Are The Champions"
I have put my code to rest. It's not perfect, but at this point, it's as good as it's going to get. It really bugs me that it isn't perfect, that it isn't optimized. Here's what I've learned about the genetic algorithm part of my project.
Random location generation is NOT the best way to generate a tag cloud. A much faster, tidier, more efficient way to generate a tag cloud is through what I call a Spiral Tetris method. (That is not a technical term; I just made it up.) Here are the principles of it.
1. Place the largest word in the center of the canvas.
2. Take the next word, and spiral out from center until you find somewhere to place it that does not intersect with the first word.
3. Continue with each word, fitting them together like Tetris pieces.
It would work something like a breadth-first search. Either way, it is not a genetic algorithm.
Part of the problem with randomness is that it takes a lot of time and power. It could, theoretically, take thousands of generations to find an optimized tag cloud through random placement. And with all of the sorting, randomizing, mixing, matching, of all of the data, it takes a loooong time. The other day, I ran my program starting at 7 am, and it was still running 12 hours later... and it hadn't even reached 100 generations... and was still at a barely positive score. Definitely nowhere near optimized.
But I have learned a lot. I learned about solving problems on my feet and thinking outside the box. As I was working on this program, I realized that I kept mating the same top chromosomes. As long as a better scoring one hasn't been generated, which push to the top, the chromosomes at positions 1, 2, 3... etc. would be the same. So I decided to randomize before I bubble sorted the scores. Let's say I had 10 chromosomes all at score 3000. And mating them made another 4 with the same score. (So I have 14 now). Instead of just putting those new 4 at the end, and mating the top 10 again to get the same 4, I mixed them up. Now, I might be mating what was 1 with 12, and 2 with 5... but they all have the same original score. This way, I'm getting more variation in the offspring generations.
Another problem I had to solve on the fly was that I was getting waaaayyyyy too many after a handful of generations. To solve this, I'm randomly killing them off when I get too many. After I randomize them, I sort them, then I take only the top chunk. Let's say I end up with 600 chromosomes, all of them with the score of 3000. None of them are really any better than the others, so I pretend I'm the Bubonic plague and kill some. That way I'm not dealing with exponentially growing populations and I continually have new chromosomes.
I also learned a lot about dealing with APIs, improved my PHP skills and learned about JSON. Granted this was long ago (early in the semester), but I remember the challenge I face with accessing and processing the Twitter data. I'm a convert... I actually kind of like JSON. It's a great way to package data!
Overall, I feel I did my best with this project, given the assigned approach and time available. Is it a perfect project? No. But the perfect project would have been outside the requirements of the assignment. In the "real world" I would have suggested taking the Spiral Tetris approach, or worked with better searches... or maybe even bring some databases in for managing data. Who knows?
The wonderful thing about Computer Science is that there are so many possibilities.
Time after time.
I've done my sentence
But committed no crime.
And bad mistakes --
I've made a few.
I've had my share of sand kicked in my face
But I've come through
(And I need just go on and on, and on, and on)...
Queen, "We Are The Champions"
I have put my code to rest. It's not perfect, but at this point, it's as good as it's going to get. It really bugs me that it isn't perfect, that it isn't optimized. Here's what I've learned about the genetic algorithm part of my project.
Random location generation is NOT the best way to generate a tag cloud. A much faster, tidier, more efficient way to generate a tag cloud is through what I call a Spiral Tetris method. (That is not a technical term; I just made it up.) Here are the principles of it.
1. Place the largest word in the center of the canvas.
2. Take the next word, and spiral out from center until you find somewhere to place it that does not intersect with the first word.
3. Continue with each word, fitting them together like Tetris pieces.
It would work something like a breadth-first search. Either way, it is not a genetic algorithm.
Part of the problem with randomness is that it takes a lot of time and power. It could, theoretically, take thousands of generations to find an optimized tag cloud through random placement. And with all of the sorting, randomizing, mixing, matching, of all of the data, it takes a loooong time. The other day, I ran my program starting at 7 am, and it was still running 12 hours later... and it hadn't even reached 100 generations... and was still at a barely positive score. Definitely nowhere near optimized.
But I have learned a lot. I learned about solving problems on my feet and thinking outside the box. As I was working on this program, I realized that I kept mating the same top chromosomes. As long as a better scoring one hasn't been generated, which push to the top, the chromosomes at positions 1, 2, 3... etc. would be the same. So I decided to randomize before I bubble sorted the scores. Let's say I had 10 chromosomes all at score 3000. And mating them made another 4 with the same score. (So I have 14 now). Instead of just putting those new 4 at the end, and mating the top 10 again to get the same 4, I mixed them up. Now, I might be mating what was 1 with 12, and 2 with 5... but they all have the same original score. This way, I'm getting more variation in the offspring generations.
Another problem I had to solve on the fly was that I was getting waaaayyyyy too many after a handful of generations. To solve this, I'm randomly killing them off when I get too many. After I randomize them, I sort them, then I take only the top chunk. Let's say I end up with 600 chromosomes, all of them with the score of 3000. None of them are really any better than the others, so I pretend I'm the Bubonic plague and kill some. That way I'm not dealing with exponentially growing populations and I continually have new chromosomes.
I also learned a lot about dealing with APIs, improved my PHP skills and learned about JSON. Granted this was long ago (early in the semester), but I remember the challenge I face with accessing and processing the Twitter data. I'm a convert... I actually kind of like JSON. It's a great way to package data!
Overall, I feel I did my best with this project, given the assigned approach and time available. Is it a perfect project? No. But the perfect project would have been outside the requirements of the assignment. In the "real world" I would have suggested taking the Spiral Tetris approach, or worked with better searches... or maybe even bring some databases in for managing data. Who knows?
The wonderful thing about Computer Science is that there are so many possibilities.
April 18, 2016
There is no decision that we can make that doesn't come with some sort of balance or sacrifice.
Simon Sinek
I'm stuck on sorting parallel arrays, and doing it efficiently. Let's back up and see what I've done since last time.
I'm working on version 2... the one that considers all the good things that the genetic algorithm will need, primarily overlap and proximity. I want the words close, but not overlapping. To determine overlap, I'm using a pixel counting loop. When I determine the size of the font, I also determine how many pixels that tag phrase will use. I also keep a running total of how many pixels should be used if there is no overlap. Then, once the words are placed on the screen, I count the total number of colored pixels on the screen. If there is overlap, that means that some pixels are shared. So if the anticipated pixel count is greater than the actual pixel count, that means there is overlap.
I also work on proximity. To track that, I keep track of the leftmost, rightmost, topmost and bottom most points of the bounding boxes for each tag phrase. Then, I look at the differences between left/right and top/bottom. They get a score based on how big the difference is.
To do the genetic algorithm, I create X number of randomly generated locations. (Right now, X is kind of small so I can test and track the results, but eventually X will be rather large.) I have a two parallel arrays: one is a simple array of the scores for each rendering. The other is a jagged array, which is an array of arrays. It is an array containing the arrays of the tag phrase locations for each rendering.
Here is my dilemma: how can I efficiently sort the scores array and keep the locations jagged array in the same order? I want to sort the bad options down and the good options up so that I can optimize the cloud. The jagged array could get quite large; each array is an array of rectangle objects, and if there are a lot of words, that is a lot of rectangles. I don't want to do any moving of the locations array that I don't have to do, or else my program will get quite slow. It's easy to sort the scores array, but the locations jagged array has to come with.
I'm trying to figure it out by mapping out how each of the basic sorts would work, but I keep getting lost. I need to figure this out...
Simon Sinek
I'm stuck on sorting parallel arrays, and doing it efficiently. Let's back up and see what I've done since last time.
I'm working on version 2... the one that considers all the good things that the genetic algorithm will need, primarily overlap and proximity. I want the words close, but not overlapping. To determine overlap, I'm using a pixel counting loop. When I determine the size of the font, I also determine how many pixels that tag phrase will use. I also keep a running total of how many pixels should be used if there is no overlap. Then, once the words are placed on the screen, I count the total number of colored pixels on the screen. If there is overlap, that means that some pixels are shared. So if the anticipated pixel count is greater than the actual pixel count, that means there is overlap.
I also work on proximity. To track that, I keep track of the leftmost, rightmost, topmost and bottom most points of the bounding boxes for each tag phrase. Then, I look at the differences between left/right and top/bottom. They get a score based on how big the difference is.
To do the genetic algorithm, I create X number of randomly generated locations. (Right now, X is kind of small so I can test and track the results, but eventually X will be rather large.) I have a two parallel arrays: one is a simple array of the scores for each rendering. The other is a jagged array, which is an array of arrays. It is an array containing the arrays of the tag phrase locations for each rendering.
Here is my dilemma: how can I efficiently sort the scores array and keep the locations jagged array in the same order? I want to sort the bad options down and the good options up so that I can optimize the cloud. The jagged array could get quite large; each array is an array of rectangle objects, and if there are a lot of words, that is a lot of rectangles. I don't want to do any moving of the locations array that I don't have to do, or else my program will get quite slow. It's easy to sort the scores array, but the locations jagged array has to come with.
I'm trying to figure it out by mapping out how each of the basic sorts would work, but I keep getting lost. I need to figure this out...
April 7, 2016
Without continual growth and progress, such words as improvement, achievement, and success have no meaning.
-Benjamin Franklin
VERSION 1 IS DONE! The data file comes in, the tag data is processed, and the words appear on the screen. Now, I have to work on the genetic algorithm.
In short, a genetic algorithm is basically survival of the fittest. The more fit something is, the longer it survives. The next question is: how do I determine fitness?
1. Words can't overlap. How do I tell if words are overlapping? I can access the location of the upper left corner of a word, but since each word varies in size (due to popularity, tag phrase length, etc.), I need to come up with a way to store the lower right corner, too. If I know those dimensions, I can tell if another word is within those dimensions.
2. Words can't be too far apart. This is a little trickier. I want to minimize the white space between words. Here's the problem I'm finding: on a canvas of any given size, the words will take up the same amount of space, regardless of whether they are close together or not. I can't just measure the white space on the canvas; it will always be the same.
I'm going to tackle part one first: determining overlap. Perhaps, as I work on that, an answer to part two will come to me. I will also try to meet with Dr. McVey (who is more familiar with C#) to see if she has suggestions.
-Benjamin Franklin
VERSION 1 IS DONE! The data file comes in, the tag data is processed, and the words appear on the screen. Now, I have to work on the genetic algorithm.
In short, a genetic algorithm is basically survival of the fittest. The more fit something is, the longer it survives. The next question is: how do I determine fitness?
1. Words can't overlap. How do I tell if words are overlapping? I can access the location of the upper left corner of a word, but since each word varies in size (due to popularity, tag phrase length, etc.), I need to come up with a way to store the lower right corner, too. If I know those dimensions, I can tell if another word is within those dimensions.
2. Words can't be too far apart. This is a little trickier. I want to minimize the white space between words. Here's the problem I'm finding: on a canvas of any given size, the words will take up the same amount of space, regardless of whether they are close together or not. I can't just measure the white space on the canvas; it will always be the same.
I'm going to tackle part one first: determining overlap. Perhaps, as I work on that, an answer to part two will come to me. I will also try to meet with Dr. McVey (who is more familiar with C#) to see if she has suggestions.
April 3, 2016
Life is 10% what happens to me and 90% how I react to it.
-Charles R. Swindoll
The past few weeks, I will admit that I haven't been reacting to what happens to me the best. I have been so busy with family and travelling for the events related to my late grandmother and I haven't been spending enough time on my capstone. It was my choice to spend extra time with them and not on my work. I haven't made wise choices lately and I need to get back on track.
So here's where I am right now. I'm almost done with V1. I'm making the tag cloud in C# instead of javascript or html. Right now, I'm reading the file in, populating a custom class with that data and determining the font size of the tag phrase. I'm still working on displaying those words on the screen, but I'm close. By the end of this week, I should be working on the genetic algorithm that will optimize placement.
Before Spring Break, I spoke to Dr. Pankratz and Dr. McVey about a shifting focus on this project. Originally, it was supposed to have more of a focus on large data. That focus has shifted. This is largely due to the way the Twitter API works. When looking at the highest trending topics, different data is returned. For example, the fields returned at the name (the tag phrase), tweet volume, if the tweet is sponsored content, the query string and the url for that query string. That's it. I don't get information about whether it has been retweeted, how many locations it has appeared in, or any of that other information.
There are other APIs that do have information like that. For example, if you were to follow one particular person's account (such as the President of the United States or the Pope), you could extract their most popular words, how many retweets, locations, etc. In the future of this project, I would consider having the student follow a particular person or a particular hashtag/topic. There are a lot more options for large data.
-Charles R. Swindoll
The past few weeks, I will admit that I haven't been reacting to what happens to me the best. I have been so busy with family and travelling for the events related to my late grandmother and I haven't been spending enough time on my capstone. It was my choice to spend extra time with them and not on my work. I haven't made wise choices lately and I need to get back on track.
So here's where I am right now. I'm almost done with V1. I'm making the tag cloud in C# instead of javascript or html. Right now, I'm reading the file in, populating a custom class with that data and determining the font size of the tag phrase. I'm still working on displaying those words on the screen, but I'm close. By the end of this week, I should be working on the genetic algorithm that will optimize placement.
Before Spring Break, I spoke to Dr. Pankratz and Dr. McVey about a shifting focus on this project. Originally, it was supposed to have more of a focus on large data. That focus has shifted. This is largely due to the way the Twitter API works. When looking at the highest trending topics, different data is returned. For example, the fields returned at the name (the tag phrase), tweet volume, if the tweet is sponsored content, the query string and the url for that query string. That's it. I don't get information about whether it has been retweeted, how many locations it has appeared in, or any of that other information.
There are other APIs that do have information like that. For example, if you were to follow one particular person's account (such as the President of the United States or the Pope), you could extract their most popular words, how many retweets, locations, etc. In the future of this project, I would consider having the student follow a particular person or a particular hashtag/topic. There are a lot more options for large data.
March 14, 2016
I am a person who continually destroys the possibilities of a future because of the numbers of alternative viewpoints I can focus on the present.
-Doris Lessing, The Golden Notebook
Re-plan. That's the motto today. This past weekend, my maternal grandmother passed away. As the adult physically closest to her final resting place, I now have a bunch of family coming in and out of my house over the next week. And with the added family and demands this week, I have to re-think how I've planned my time. Furthermore, there will be a memorial service in North Carolina the week after spring break. Between planning the travel, packing, travelling and spending time with family out there, I will lose the better part of a week the week after spring break.
So how will I adjust my plans and still deliver an on-time product? How will I focus on what is essential and eliminate the "alternative viewpoints" I'm seeing in the present?
In short, I think I'm going to spend less time reinventing the wheel.
I was supposed to be done with V1 by the end of this week. I found a great skeleton for a Javascript tag cloud. It handles a lot of the stuff I had no idea how to work with, such as the graphical rendering of the sprites. I had no idea where to start with the rendering of the words; this tag cloud has the rendering in place. I will have to gut it quite a bit, though, since it doesn't do exactly what I need it to do, in a way I need it to do it. There isn't a genetic algorithm; it doesn't process the dataset in a way I want it to, etc. Instead of trying to start the graphical rending from scratch (which is what I had planned on), I will borrow the frame of a wheel from someone else.
So this week will be spent gutting that code. Next week (Spring Break) will be spent adding the appropriate modifications to get it just running. Normally, this would be a one-week kind of assignment, but with everything coming up, I need to allow myself a little more time. The week after, when I will be travelling to North Carolina, I will start genetic algorithm work. I don't expect to get far that week, but I want to get a start.
-Doris Lessing, The Golden Notebook
Re-plan. That's the motto today. This past weekend, my maternal grandmother passed away. As the adult physically closest to her final resting place, I now have a bunch of family coming in and out of my house over the next week. And with the added family and demands this week, I have to re-think how I've planned my time. Furthermore, there will be a memorial service in North Carolina the week after spring break. Between planning the travel, packing, travelling and spending time with family out there, I will lose the better part of a week the week after spring break.
So how will I adjust my plans and still deliver an on-time product? How will I focus on what is essential and eliminate the "alternative viewpoints" I'm seeing in the present?
In short, I think I'm going to spend less time reinventing the wheel.
I was supposed to be done with V1 by the end of this week. I found a great skeleton for a Javascript tag cloud. It handles a lot of the stuff I had no idea how to work with, such as the graphical rendering of the sprites. I had no idea where to start with the rendering of the words; this tag cloud has the rendering in place. I will have to gut it quite a bit, though, since it doesn't do exactly what I need it to do, in a way I need it to do it. There isn't a genetic algorithm; it doesn't process the dataset in a way I want it to, etc. Instead of trying to start the graphical rending from scratch (which is what I had planned on), I will borrow the frame of a wheel from someone else.
So this week will be spent gutting that code. Next week (Spring Break) will be spent adding the appropriate modifications to get it just running. Normally, this would be a one-week kind of assignment, but with everything coming up, I need to allow myself a little more time. The week after, when I will be travelling to North Carolina, I will start genetic algorithm work. I don't expect to get far that week, but I want to get a start.
March 1, 2016
Your calm mind is the ultimate weapon against your challenges. So relax.
-Bryant McGill
This week, I am going to put my project on hold for a few days. I am attending the Sigma Tau Delta convention starting tomorrow. (It's a national honor society for English majors... yes, I'm a double major. I've been invited to present a flash fiction collection I wrote... such an honor!) So next week, there will be no new blog. I may make minor steps between now and then, and if there is anything to note, I will blog about it.
Anyway, I've more-or-less finished one part of my project: dealing with Twitter. I am able to access the Twitter API, bring in the data, parse it into relevant pieces and write it to a .txt file. I am also eliminating bad data. Sometimes, the API returns a null value for the tweet_volume field, so if the tweet_volume is null, I don't store it. I may tweak the tweets as I go on, but I'm pretty sure I'm pretty close to being done with this.
This is a good place to pause my work. I'm not in the middle of anything huge. I'm still poking around looking at sample tag cloud generators online and bookmarking examples I may be interested in. When I get back, I'm going to dive in to V1 of the tag cloud generator: just make a cloud. From there, I will work on V2: an optimized cloud.
-Bryant McGill
This week, I am going to put my project on hold for a few days. I am attending the Sigma Tau Delta convention starting tomorrow. (It's a national honor society for English majors... yes, I'm a double major. I've been invited to present a flash fiction collection I wrote... such an honor!) So next week, there will be no new blog. I may make minor steps between now and then, and if there is anything to note, I will blog about it.
Anyway, I've more-or-less finished one part of my project: dealing with Twitter. I am able to access the Twitter API, bring in the data, parse it into relevant pieces and write it to a .txt file. I am also eliminating bad data. Sometimes, the API returns a null value for the tweet_volume field, so if the tweet_volume is null, I don't store it. I may tweak the tweets as I go on, but I'm pretty sure I'm pretty close to being done with this.
This is a good place to pause my work. I'm not in the middle of anything huge. I'm still poking around looking at sample tag cloud generators online and bookmarking examples I may be interested in. When I get back, I'm going to dive in to V1 of the tag cloud generator: just make a cloud. From there, I will work on V2: an optimized cloud.
February 21, 2016
The over-all point is that new technology will not necessarily replace old technology, but it will date it. By definition. Eventually, it will replace it. But it's like people who had black-and-white TVs when color came out. They eventually decided whether or not the new technology was worth the investment.
-Steve Jobs
I'm having a dated technology problem. Here's the rub: Twitter APIs return data as a JSON string. (JSON stands for JavaScript Object Notation.) Instead of returning a bunch of data haphazardly, it returns it as objects. (Yay for OOP!) This is, honestly, great. It will make for easier parsing. It is faster than sending large strings.
The problem? Our old compsci02.snc.edu doesn't know what to do with JSON. JSON has built in functions, like json_decode, which will bust apart the JSON objects into an associative array. If I can get json_decode working, this will be great. It's a really simple way to parse the data. But compsci02.snc.edu doesn't recognize JSON functions.... so I'm stalled.
I'm going to look more into this. In the mean time, I'm going to start working on Version 1 of the tag cloud generator. V1 needs to render the data in proportion to size, avoid overlapping, and prevent words from going off the screen. I'm not going to worry about the genetic algorithm to optimize the tag cloud in V1. Right now, I'm concerned with getting the data up and making that rendering readable. Once that works, I will work on Version 2, which will include multiple renderings and a genetic algorithm that will produce an optimized tag cloud.
UPDATE: Thanks a bunch to Jordan Henkel! He gave me some advice for using JSON on compsci02! We need to upgrade the php in order for it to use JSON (and other things). He provided me with upgrade.php, which I will be including in the directory that houses my php file. Then, I just need to add the line include_once("upgrade.php"); at the top. (Note: I haven't actually done this yet, it is on my plate for tomorrow. I've spent all day on this and it's time to get my little girl to bed. I will let you know how it turns out.)
-Steve Jobs
I'm having a dated technology problem. Here's the rub: Twitter APIs return data as a JSON string. (JSON stands for JavaScript Object Notation.) Instead of returning a bunch of data haphazardly, it returns it as objects. (Yay for OOP!) This is, honestly, great. It will make for easier parsing. It is faster than sending large strings.
The problem? Our old compsci02.snc.edu doesn't know what to do with JSON. JSON has built in functions, like json_decode, which will bust apart the JSON objects into an associative array. If I can get json_decode working, this will be great. It's a really simple way to parse the data. But compsci02.snc.edu doesn't recognize JSON functions.... so I'm stalled.
I'm going to look more into this. In the mean time, I'm going to start working on Version 1 of the tag cloud generator. V1 needs to render the data in proportion to size, avoid overlapping, and prevent words from going off the screen. I'm not going to worry about the genetic algorithm to optimize the tag cloud in V1. Right now, I'm concerned with getting the data up and making that rendering readable. Once that works, I will work on Version 2, which will include multiple renderings and a genetic algorithm that will produce an optimized tag cloud.
UPDATE: Thanks a bunch to Jordan Henkel! He gave me some advice for using JSON on compsci02! We need to upgrade the php in order for it to use JSON (and other things). He provided me with upgrade.php, which I will be including in the directory that houses my php file. Then, I just need to add the line include_once("upgrade.php"); at the top. (Note: I haven't actually done this yet, it is on my plate for tomorrow. I've spent all day on this and it's time to get my little girl to bed. I will let you know how it turns out.)
Feb 15, 2016
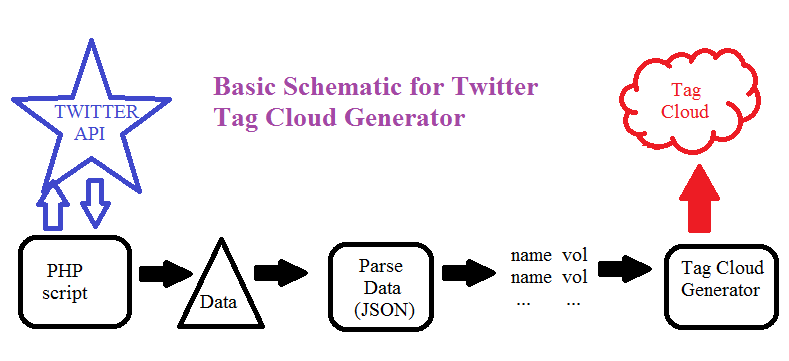
Planning is bringing the future into the present so that you can do something about it now.
-Alan Lakein
So I've come up with a schematic for my program... a plan. I figured out how to access the data from Twitter so that I can retrieve the top trending data for a given location (right now, I'm using the United States).
I use a PHP script to access the Twitter API, and it returns the top 50 at that moment. It returns the data as a JSON string with multiple fields. Eventually, I need to parse it out so that I just have the name and the tweet volume (the number of times it was tweeted). Once I have the data parsed, I can send it to the tag cloud generator. The tag cloud generator will, at first, use a fixed size for the font of a trending topic based on popularity. (Eventually, I may make the size more fluid to make things fit better). The generator will work with the X,Y coordinates to create the cloud.
My next steps:
1. Work on parsing the JSON strings into a data file
2. Find the best examples of tag cloud generators that i can find online. What are they doing well? What aren't they doing well? What can I do better?
One concern right now: the Twitter API is returning a lot of NULL values for "tweet volume." I'm looking into why. I guess it's a "new" feature, so it may get better. But I need to keep this in my mind as I work. I doubt that by the end of the semester, it will be working perfectly and never returning a null value, so I need to plan for null "tweet volumes."
-Alan Lakein
So I've come up with a schematic for my program... a plan. I figured out how to access the data from Twitter so that I can retrieve the top trending data for a given location (right now, I'm using the United States).
I use a PHP script to access the Twitter API, and it returns the top 50 at that moment. It returns the data as a JSON string with multiple fields. Eventually, I need to parse it out so that I just have the name and the tweet volume (the number of times it was tweeted). Once I have the data parsed, I can send it to the tag cloud generator. The tag cloud generator will, at first, use a fixed size for the font of a trending topic based on popularity. (Eventually, I may make the size more fluid to make things fit better). The generator will work with the X,Y coordinates to create the cloud.
My next steps:
1. Work on parsing the JSON strings into a data file
2. Find the best examples of tag cloud generators that i can find online. What are they doing well? What aren't they doing well? What can I do better?
One concern right now: the Twitter API is returning a lot of NULL values for "tweet volume." I'm looking into why. I guess it's a "new" feature, so it may get better. But I need to keep this in my mind as I work. I doubt that by the end of the semester, it will be working perfectly and never returning a null value, so I need to plan for null "tweet volumes."
Feb 9, 2016
How does a project get to be a year late? ... One day at a time.
-Frederick P. Brooks, Jr.
I am behind, and I know it. I was pretty sick this weekend, so a weekend dedicated to planning, drawing out and moving forward was spend moving backwards. I forgot where I was at the end of last week. I forgot where I wanted to go. I moved back.
Now I'm playing catch-up. Catch-up with my other classes, catch-up with the classwork for this one, catch-up for this project.
I have made some decisions.
1. I don't care much for Kristen's code. Nothing personal, but it's a bit of a mess. She was bringing in data through the Twitter API and storing it a C-based language data structure. This is probably where the bug lies. The Twitter API likes JSON... and it probably has some sort of data, character or something that she's not processing correctly. And I don't want to deal with it.
2. I'm going to do this in Javascript. It should make dealing with the Twitter API's data much easier. Also, I've found some examples of tag cloud generation ... and all of them are in Javascript/HTML. So let's just keep this all web-based.
3. I'm going to look at hashtags trending near De Pere, WI. Keep it fun, keep it local. I have to use some sort of search criteria, but since I don't want to look for particular tags or people, I'm going to utilize the geotagging feature and search for the most popular Tweets near De Pere.
Next steps:
1. Do more research on the Twitter API. Get to know more about it and how it structures the data.
2. Build my host for this. Jordan suggested I get a JQUERY starter kit, which will minimize the Javascript overhead. I need to make this page and do some basic testing: get a "Hello World!" out there.
3. Work on processing Twitter API data. How am I going to store this data? How am I going to prepare this data to be used by the tag cloud generator?
4. Look more in-depth at tag cloud code I can find online. See what they are doing... and play with it. Work with a consistent data set (like a long poem or chapter from a book) instead of Twitter for now. How are they optimizing space? What are they hard-coding and what aren't they? How do they import and manipulate data? Most importantly... what can I do better?
-Frederick P. Brooks, Jr.
I am behind, and I know it. I was pretty sick this weekend, so a weekend dedicated to planning, drawing out and moving forward was spend moving backwards. I forgot where I was at the end of last week. I forgot where I wanted to go. I moved back.
Now I'm playing catch-up. Catch-up with my other classes, catch-up with the classwork for this one, catch-up for this project.
I have made some decisions.
1. I don't care much for Kristen's code. Nothing personal, but it's a bit of a mess. She was bringing in data through the Twitter API and storing it a C-based language data structure. This is probably where the bug lies. The Twitter API likes JSON... and it probably has some sort of data, character or something that she's not processing correctly. And I don't want to deal with it.
2. I'm going to do this in Javascript. It should make dealing with the Twitter API's data much easier. Also, I've found some examples of tag cloud generation ... and all of them are in Javascript/HTML. So let's just keep this all web-based.
3. I'm going to look at hashtags trending near De Pere, WI. Keep it fun, keep it local. I have to use some sort of search criteria, but since I don't want to look for particular tags or people, I'm going to utilize the geotagging feature and search for the most popular Tweets near De Pere.
Next steps:
1. Do more research on the Twitter API. Get to know more about it and how it structures the data.
2. Build my host for this. Jordan suggested I get a JQUERY starter kit, which will minimize the Javascript overhead. I need to make this page and do some basic testing: get a "Hello World!" out there.
3. Work on processing Twitter API data. How am I going to store this data? How am I going to prepare this data to be used by the tag cloud generator?
4. Look more in-depth at tag cloud code I can find online. See what they are doing... and play with it. Work with a consistent data set (like a long poem or chapter from a book) instead of Twitter for now. How are they optimizing space? What are they hard-coding and what aren't they? How do they import and manipulate data? Most importantly... what can I do better?
Feb 2, 2016
Productivity is never an accident. It is always the result of a commitment to excellence, intelligent planning, and focused effort.
-Paul Mayer
I need to get organized. I have ideas, I have plans, I even have some code to start with, since I'm taking this project over. But so far, this first week of the semester, I have yet to get myself organized. I'm still trying to figure out the school-life balance, with having a spouse who works evenings and a kid who... well, doesn't. I need to figure out what times I will be working on this stuff, and if that will be enough.
-Paul Mayer
I need to get organized. I have ideas, I have plans, I even have some code to start with, since I'm taking this project over. But so far, this first week of the semester, I have yet to get myself organized. I'm still trying to figure out the school-life balance, with having a spouse who works evenings and a kid who... well, doesn't. I need to figure out what times I will be working on this stuff, and if that will be enough.