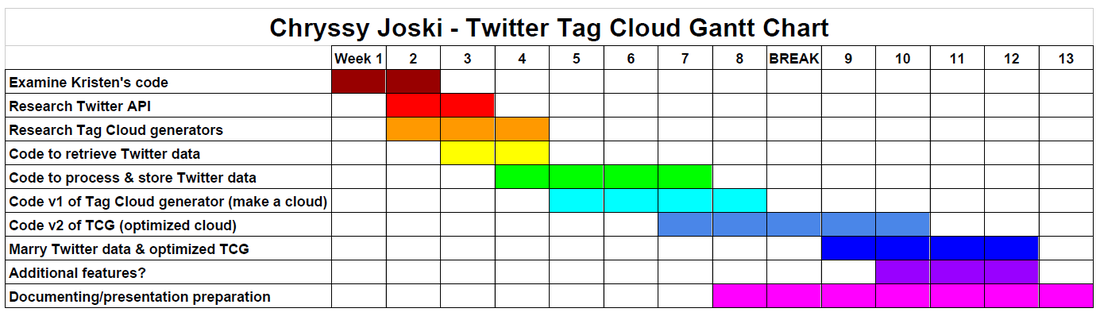
Gantt Chart: A Plan for Progress
The Future of the Project |
If another student were to take this project over in the future, I have two main pointers for you.
1. Do not use a genetic algorithm. Place the words in the cloud using a method similar to a breadth-first search. Place the largest word in the center, then develop an algorithm to find the next available spot (where there is no overlap) to place the next largest word, slowly moving out from center. The randomness of a genetic algorithm is not an efficient way to produce an optimized tag cloud. Some of the functions I have developed can be re-used, such as the pixel counting function, the TagPhrase class, etc. There may have to be expansions to the class, depending on suggestion number 2. I'm only tracking the Tag Phrase and the Tweet Volume... you may need to track other data. 2. If you want to work with Large Data, use a different API. Do not use trending topics. Follow one person, one business, one topic. You can pull more data from those APIs than from the trending topics API. For example, you can follow SNC, and do a tag cloud based on keywords in their tweets, and track the retweets, locations, likes, etc. There is much more data inherent in those API formats. |
Presentation Slideshow |
Below is the slideshow of my end-of-project slideshow. It includes notes for the future, an overview of my work, and some information about genetic algorithms. (It was developed using Google Slides, so I apologize for any odd layouts that may have resulted during the conversion to the PowerPoint format.)
| ||