Post 0
2/3/2026
Over the past two weeks, I have worked towards formalizing my project goals. The idea I had initially for my project fell through when the data was not easily accessible. With the help of Dr. Dunbar and BMVP, I was able to pivot to another topic. In addition to formalizing a project, I have spent time learning about recombination Markov chains. I have also been working on this website. I did not know any HTML coming into this, so I have learned a lot about this too!
Post 1
2/8/2026
The first step in my project was to gather data on Wisconsin Wards, which will be needed to create adjacency graphs to build maps. I have also been looking at the Wisconsin Elections Commission site to see what voter data is available at the ward level. This will shape how a user may eventually interact with the results. I have also been considering how I might store my data to best suit the end product.
Post 2
2/13/2026
This week has been a bit slow for me, but I did begin working on understanding the algorithms on smaller examples. Using square grids, the adjacency lists are much easier to create, so I have been working on looking at graph decomposition for those examples. Dr. Dunbar has created a few more examples, split into color districts, for me to begin working on creating random walks for. These will also help me work on the map visualization.
Post 3
2/18/2026
I have a graph! This week felt like the first time the mathematics of my project really became tangible. Up to this point, I had been reading about recombination Markov chains and working through small graph examples somewhat abstractly. Now, I am actually implementing the algorithm step by step: merging adjacent districts, constructing a spanning tree of the combined region, and cutting random edges to create new connected districts. Watching this process unfold on a 5x5 and 50x50 grid has made the theory feel much more concrete. From a mathematical standpoint, the spanning tree construction has been especially interesting to me. Enforcing contiguity in a redistricting algorithm is powerful. When randomly cutting one edge of the tree, the structure immediately decomposes into connected components. On a more personal level, this week involved a lot of debugging and restructuring. I had to carefully think about how adjacency lists, district labels, and JSON files interact. Getting the algorithm to update district assignments correctly and then render them visually forced me to be precise about how data flows through my program. Once this works consistently on grid examples, I will feel much more confident scaling the algorithm to Wisconsin ward data.
Post 4
2/28/2026
This week, I have discovered a massive flaw in my algorithm. This did not occur to me until I tested enough cases on my 50x50 grid below. The initial districting for the examples below was equal columns of 5 colors. I was finding that my 50x50 grid district maps were very consistently red. I had some trouble rationalizing this because red was the leftmost initial column, meaning it had fewer adjacencies than the center columns. This was happening because I was using a BFS spanning tree to make a random cut into two components. This has a very high probability of cutting very unevenly sized districts. I have not yet introduced a population component to ensure equally sized districts; however, that would have likely failed anyway. Not all trees are guaranteed to have a cut edge that would produce equal subgraphs. I have a few other options for how I can accomplish this task.
Another set of options I am considering involves moving away from cutting spanning trees altogether and instead redefining the transition step of the Markov chain. One possibility is to implement a flip-based method, where border vertices are swapped between adjacent districts. I would need to enforce connectivity and approximate population balance at each step. Although flips are more local and may mix more slowly than large recombination moves, they are well understood and avoid the structural imbalance issues inherent in random tree cuts. A second alternative would be a growth-based approach. I could start from a boundary node and grow a district outward until a target population is reached. Finally, there may be a hybrid strategy that selectively searches for more interior edges in a spanning tree. By walking inward from terminal vertices, cuts are more likely to produce balanced components. I am trying to figure out which option will be the most feasible for this project




Post 5
3/7/2026
I like trees again! This week I began looking into Wilson's algorithm as a way to generate better spanning trees. In my earlier approach, I was using a BFS tree, which introduced a lot of structure and bias. Wilson's algorithm instead produces a uniform spanning tree, meaning every possible spanning tree of the graph is equally likely. It works by performing random walks. Starting from an arbitrary root vertex, a random walk begins from another randomly selected vertex and continues until it hits the existing tree. If the walk forms a loop, the loop is erased. The resulting path is then added to the tree, and this process repeats until all vertices are included. While this fixes the bias in the tree generation, it does not solve the problem of uneven cuts. Even with a perfectly random spanning tree, most edges separate very small subtrees from the rest of the graph. To address this, I am experimenting with selecting only edges that produce near-equal components when cut. This should help ensure that recombination steps actually generate districts of comparable size, rather than repeatedly creating very uneven partitions. I will likely need to find a more efficient way to do this.
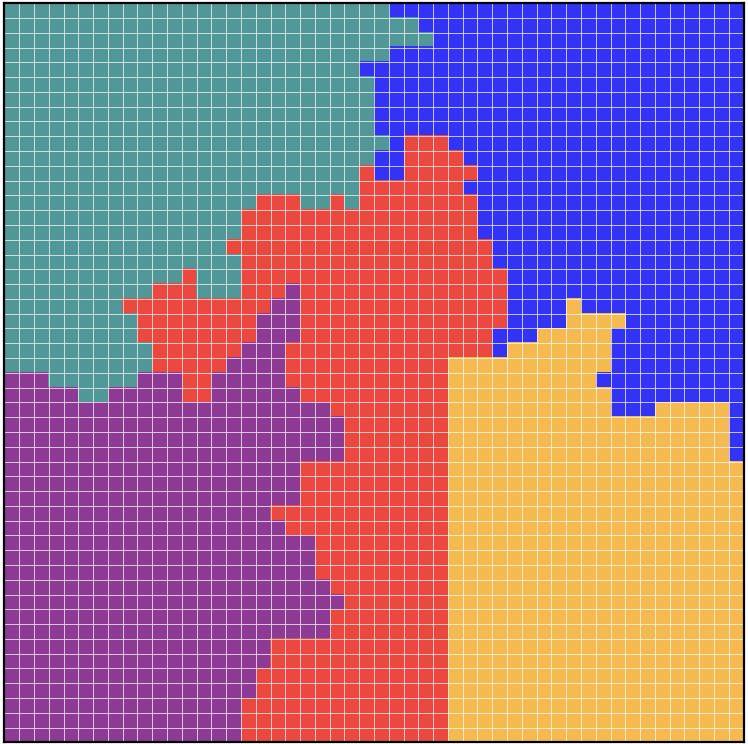
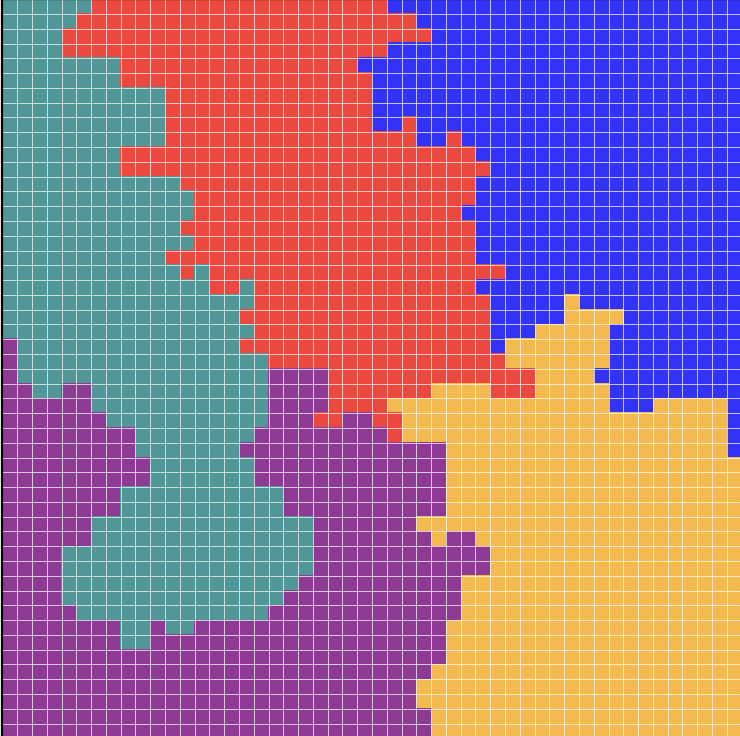
Post 6
3/14/2026
This week, I have made some minor changes to my algorithm. Originally, when testing for equal cuts in my spanning tree, I randomly selected edges and made a cut if possible. Often this was not the case, so I was iterating over 100 checks and discarding a tree if I did not find a valid cut within those 100 checks. I have changed my algorithm to now check every possible edge and store the ones that produce a valid cut. From that subset, a random edge is selected and cut. This is slower, but avoids throwing away usable trees.
Additionally, when checking whether a cut was valid, I was comparing subtree sizes locally rather than relying on a global population count. This could lead districts to lose area over time in a Monte Carlo simulation. I have updated this to compare to a target population per district. The next step is to apply this to Wisconsin. I have shapefiles for the ward mappings, but I am struggling to find population totals at that level.
Post 7
3/27/2026
Currently, I am working on getting my algorithm to apply to Wisconsin. I have a shape file and am able to render graphics using GeoPandas. I am running into some issues I did not have with the grids. The initial distribution is very important to ensure connectivity within districts. Initially, I tried randomly assigning initial districts. This was a VERY bad idea; the resulting map resembled confetti. I also tried rows/columns like I had done the grids, but this was also a bad idea, as that does not guarantee initial connectivity. I think the best course is to use the current district map used by the state, or to use a different method, such as 'growing districts' from a random ward to create an initial map.
Post 8
4/5/2026
This week was a major turning point in my project. Using a new shapefile I was able to transition from grid-based simulations to real Wisconsin ward data. I encountered an issue that, at first, looked like a bug in my ReCom implementation, but turned out to be something much more interesting. Using the statewide ward shapefile, I successfully built an adjacency graph based on geometric intersections and incorporated population data to enforce balanced district splits. I noticed that certain districts, particularly the blue and yellow regions in my visualizations, were not changing at all, even after 500 of accepted steps.
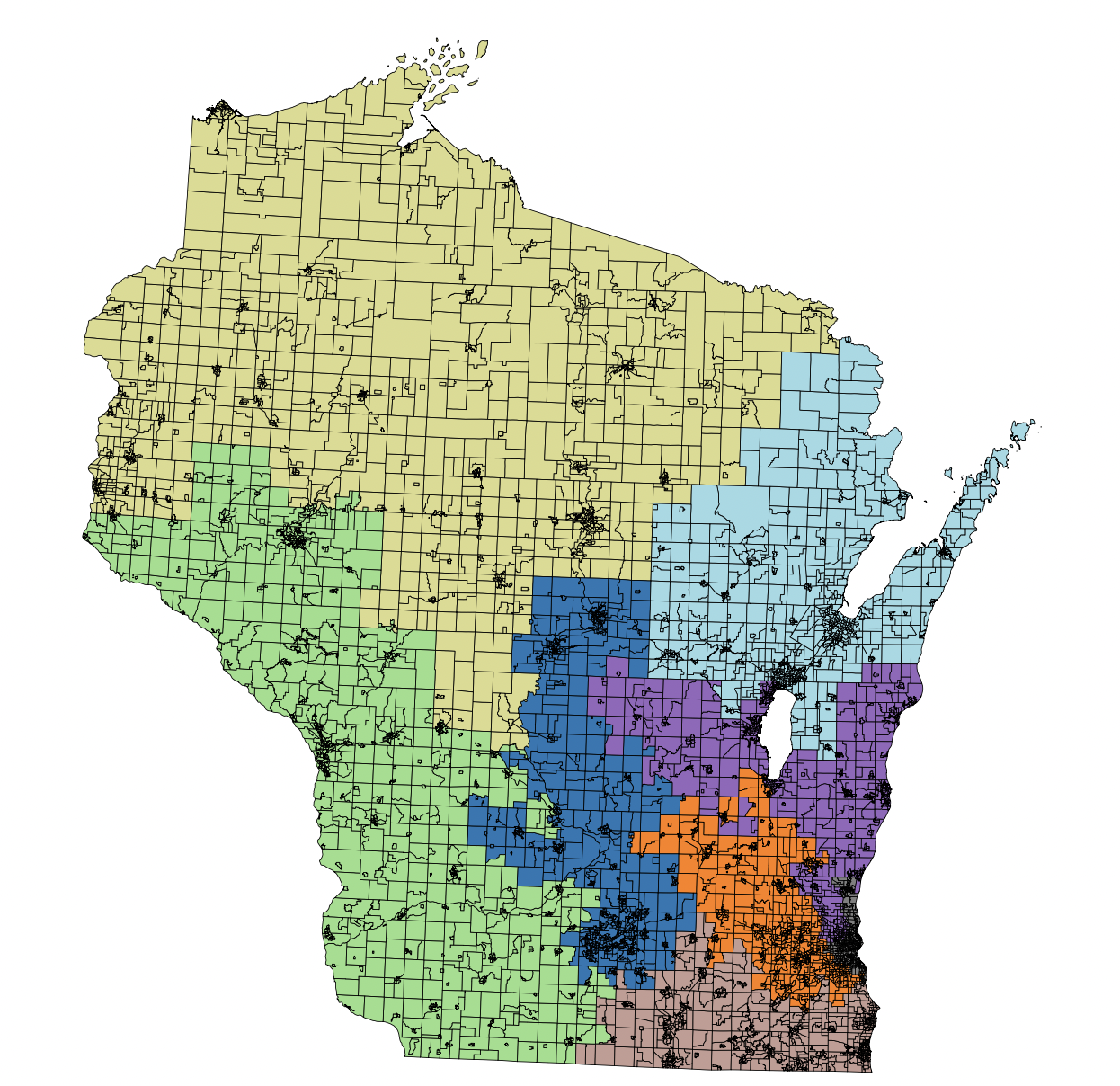
By explicitly checking connectivity, I discovered that some of the initial districts were not connected. In particular, districts 7 and 8 each contained small island components. The ReCom algorithm assumes that each district is connected. When this assumption is violated, recombination steps involving those districts frequently fail because the merged graph cannot form a valid spanning tree. To fix this, I found the wards with a null adjacency list. I then found the ward that was geographically the closest, and added them to each other's adjacency lists. After applying this fix, the districts became fully connected, and the recombination chain behaved much more as expected. Moves are now accepted significantly more frequently.
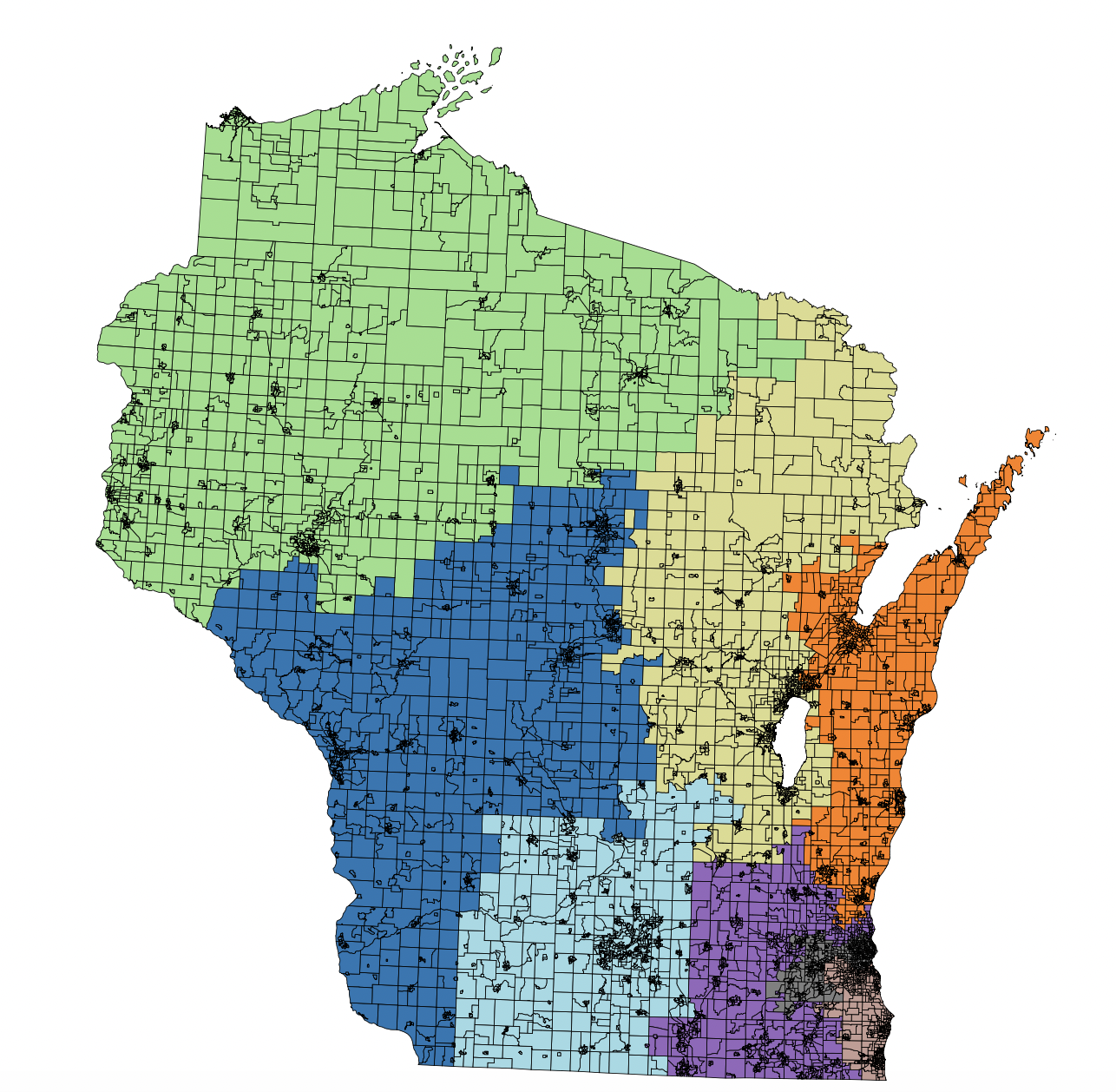
Post 9
4/11/2026
I thought I was ready to start looking at some of the data across my maps; however, I have noticed yet another problem in the map creation step. I was allowing point adjacencies. This can make the map appear disconnected and allow the districts to snake into each other. This sort of queen adjacency is not ideal. I needed to transition to a rook sort of adjacency. The strategy I used is detailed here.
Post 10
4/18/2026
I have 1500 maps! Over the past week, I have run my simulation using each map as the initial state for the following map. For this simulation, I used a
1% population tolerance between wards and required 10 successful ReCom steps before a map was saved. This took roughly 50 attempts per map. The JSON files I used to store these maps
only contain the data on population, ward ID, and an adjacency list. To analyze these maps, I pulled the voter and demographic data from my shapefile. I then iterated through each of my maps
, aggregating 2-party voter data grouped by ward. Using this information, I was able to create distributions of how many wards each party won for a given election. Observe The 2016 presidental election district
breakdown below. Notice the histogram is mirrored, just using a different party as the baseline.
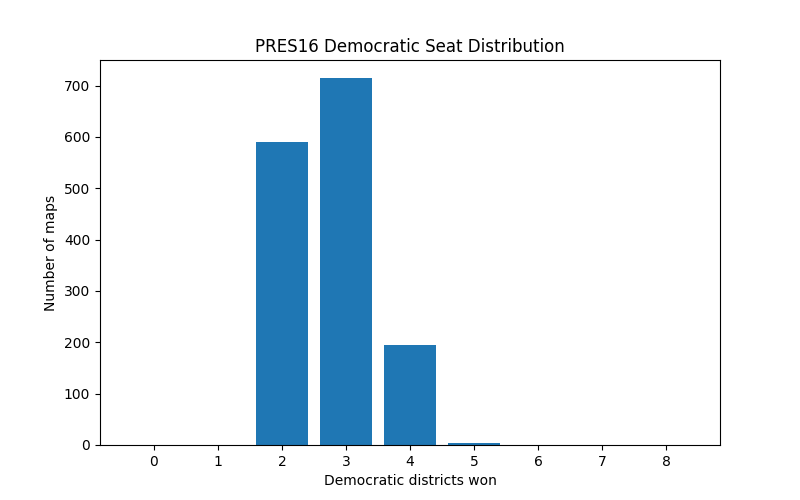
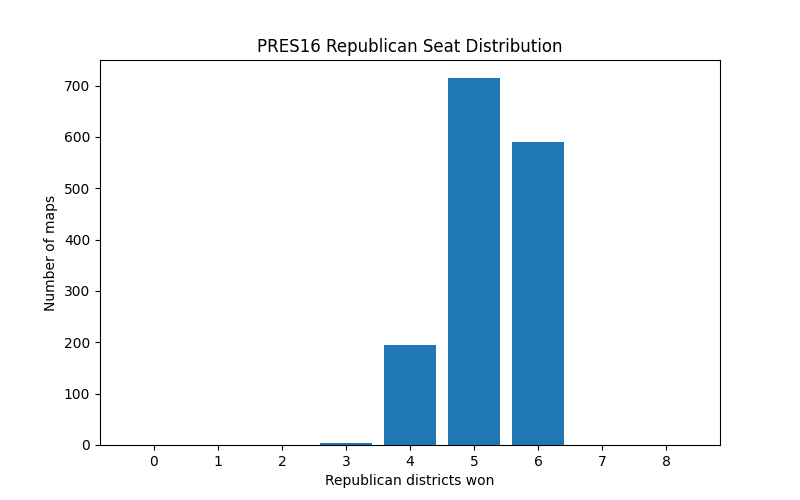
Another aspect I wanted to look at was voter demographics. Per Thornburg v. Gingles (1986), the Supreme Court held that when possible, a majority-minority A district should be created. To look at this, for each district, I was able to find the share of non-white voters. In 449 of the 1500 maps generated, I was able to produce exactly 1 majority-Minority district. This district was typically centered around Milwaukee. I was pleased to see that the current WI district plans also upheld this.
Post 11
4/25/2026
I have spent much of this week working on my project dashboard! It is linked in the menu above, so check it out. I think that will do a better job demonstrating what I have accomplished over the past week than anything I could write here. Now I am trying to get my slides and my story together for demo day.
Post 12
5/2/2026
This week, I finalized my presentation and practiced my talk. See my slides here. The visuals took a fair amount of time to create, so that took up much of my time this week. It was important that I was able to present this in a way that people were able to understand both the project and its significance. This week in particular, the topic of majority-minority districts was especially relevant. Wednesday, after I had already made my slides, the Supreme Court weighed in on majority-minority districts. I am writing this blog post after my presentation, and I believe I was able to communicate the political outcomes in this project in a way that highlighted the project rather than dividing the audience politically.